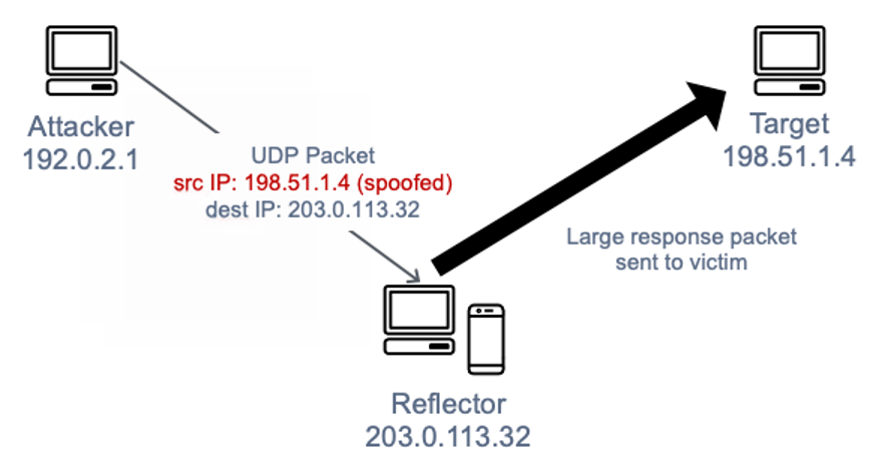
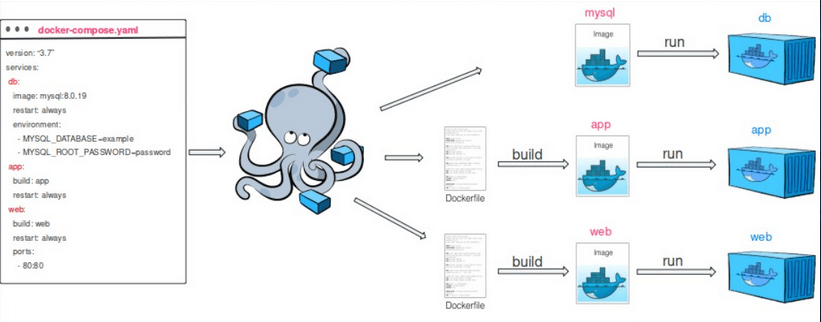
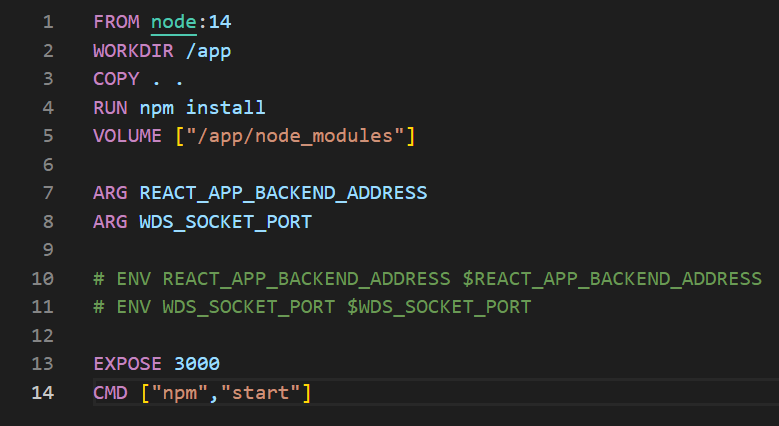
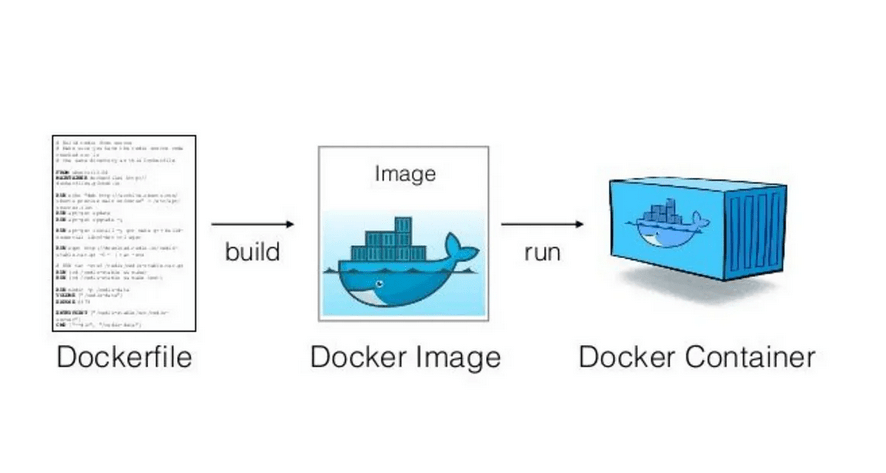
Dzisiaj opowiemy wam, czym właściwie jest wirtualizacja, jakie są jej rodzaje oraz przedstawimy wam informacje o dobrych zasadach projektowych zaproponowanych przez firmę Redhat w 2017 roku, które dotyczą kontenerów wdrażanych w środowiskach orkiestracyjnych, w tym chmurowych. Bardzo podobne zasady obserwujemy w całym świecie informatyki, w tym w programowaniu np. DRY, KISS czy zasady SOLID. Jeśli chcesz przeczytać o czystym kodzie, to zachęcamy do zapoznania się z naszą serią dotyczącą Clean Code.
Czym jest hypervisor?
Aby zrozumieć na czym polega wirtualizacja w systemach operacyjnych należy wyjaśnić podstawowe pojęcie dotyczące tego zagadnienia - hypervisor, inaczej hipernadzorca. Jest to komponent oprogramowania, który umożliwia tworzenie i zarządzanie maszynami wirtualnymi (VM) na fizycznej maszynie. Hipernadzorca znajduje się pomiędzy fizycznym sprzętem (hardware) a maszynami wirtualnymi i umożliwia równoczesne uruchamianie wielu systemów operacyjnych na pojedynczej maszynie.
Istnieją dwa podstawowe rodzaje hypervisorów:
Type 1 Hypervisor (Bare Metal Hypervisor) - spotykany częściej w rozwiązaniach serwerowych, w tym w centrach danych. Działa on bezpośrednio na fizycznym sprzęcie, bez potrzeby hostującego systemu operacyjnego. Ma bezpośredni dostęp do zasobów sprzętowych. Przykładami oprogramowania działającymi w ten sposób są np. Microsoft Hyper-V, Citrix XenServer oraz VMware ESXi.
Type 2 Hypervisor (Hosted Hypervisor) - spotykany częściej na komputerach użytkowników. Działa on na hostującym systemie operacyjnym (host OS). Polega na nim w celu zarządzania zasobami sprzętowymi, a także dostarcza dodatkową warstwę abstrakcji. Przykładami oprogramowania działającymi w ten sposób są: VMware Workstation, Oracle VirtualBox i Parallels Desktop.
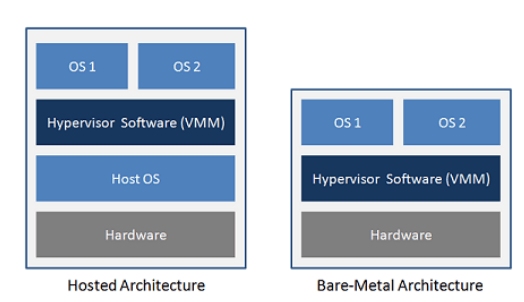
Rysunek 1 - architektura typu 2 kontra typu 1, źródło vgyan.in
Czym jest wirtualizacja, jakie są jej rodzaje?
Wirtualizacja jest powszechną techniką w informatyce, która polega na tworzeniu instancji sprzętu lub oprogramowania na jednym fizycznym systemie komputerowym. Inaczej mówiąc chodzi o symulowanie istnienia zasobów logicznych, które korzystają pod spodem z komponentów fizycznych. Celem wirtualizacji jest efektywne wykorzystanie zasobów sprzętowych oraz umożliwienie izolacji różnych środowisk i aplikacji, co może prowadzić do poprawy wydajności, bezpieczeństwa oraz ułatwiać zarządzanie. Istnieją różne podziały wirtualizacji jak np. parawirtualizacja oraz pełna wirtualizacja.
W podejściu pełnej wirtualizacji hypervisor pełni replikuje hardware. Główną korzyścią tej metody jest zdolność do uruchamiania oryginalnego systemu operacyjnego bez żadnych modyfikacji. W trakcie pełnej wirtualizacji system operacyjny gościa pozostaje całkowicie nieświadomy faktu, że jest zwirtualizowany. To podejście korzysta zarówno z takiej techniki jak wykonanie bezpośrednie (mniej kluczowe komendy korzystają z kernela z pominięciem hypervisora) jak i z translacji binarnej, czyli tłumaczenia komend. W rezultacie zwykłe instrukcje CPU są wykonywane bezpośrednio, podczas gdy bardziej wrażliwe instrukcje CPU są dynamicznie tłumaczone. Aby poprawić wydajność, hypervisor może przechowywać w pamięci podręcznej niedawno przetłumaczone instrukcje.
W parawirtualizacji natomiast, hypervisor nie symuluje podlegającego sprzętu. Zamiast tego dostarcza mechanizm hypercalls. System operacyjny gościa wykorzystuje je do wykonania wrażliwych instrukcji CPU. Ta technika nie jest tak uniwersalna jak pełna wirtualizacja, ponieważ wymaga wykonania modyfikacji w systemie operacyjnym gościa, jednak zapewnia lepszą wydajność. Warto dodać, że system operacyjny gościa zdaje sobie sprawę, że jest zwirtualizowany.
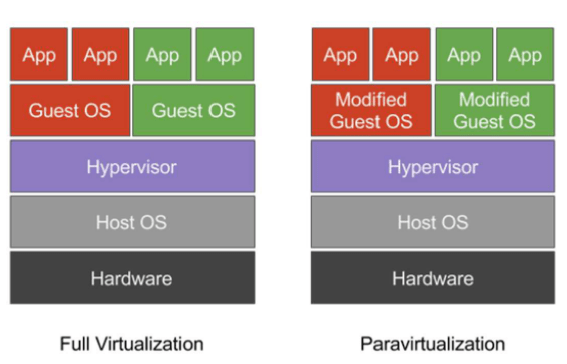
Rysunek 2 - Różnica między wirtualizacją i parawirtualizacją
Czym jest konteneryzacja?
Konteneryzacja natomiast to rodzaj wirtualizacji na poziomie systemu operacyjnego, gdzie kontenery dzielą się zasobami tego samego systemu operacyjnego, zachowując jednocześnie pewną izolację między sobą. W porównaniu do innych form wirtualizacji, kontenery wprowadzają minimalny narzut (ze względu na współdzielony system hosta), co oznacza, że zużycie dodatkowych zasobów jest znacznie niższe niż w przypadku maszyn wirtualnych. Zasoby mogą być przydzielane i zwalniane w pełni dynamicznie przez system operacyjny hosta. Niestety, separacja kontenerów jest ograniczona w porównaniu do klasycznych rozwiązań wirtualizacyjnych.
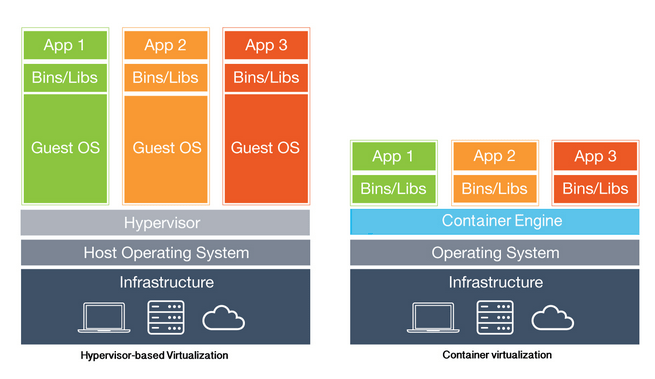
Rysunek 3 - Wirtualizacja kontra konteneryzacja, źródło blackmagicboxes.com
Najpopularniejsze sposoby wykorzystania technologii konteneryzacji to:
- Kontenery systemowe (system containers, infrastructure containers) – podobnie jak wirtualne maszyny oferują środowisko określonego systemu operacyjnego razem z zainstalowanymi bibliotekami oraz narzędziami. Tak jak systemy na maszynach wirtualnych mają za zadanie działać przez dłuższy okres.
- Kontenery aplikacyjne (application containers) – służą do uruchomienia określonej aplikacji, lub fragmentu aplikacji w przypadku architektury mikroserwisowej. Kontenery aplikacyjne nazywa się także efermalnymi ze względu na to, że instancja jest chwilowa. Przy nowym wdrożeniu aplikacji obraz aplikacji zmieni się i wdrażany jest nowy kontener, a poprzedni kasowany.
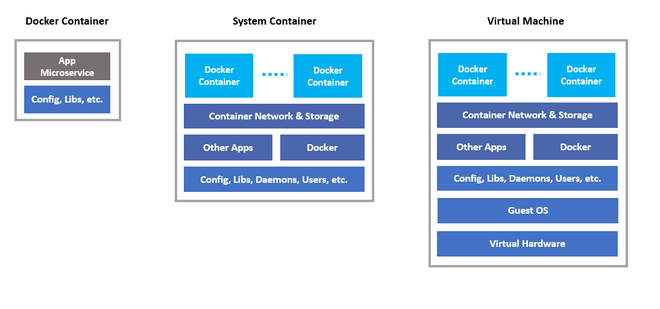
Rysunek 4 - porównanie kontenera aplikacyjnego, systemowego oraz wirtualnej maszyny, źródło: nestybox
Nested virtualization
Ciekawym rozwiązaniem jest także nested virtualization. Z pomocą kontenerów systemowych lub maszyn wirtualnych możemy wprowadzić dodatkową warstwę abstrakcji. Po prawej możemy zobaczyć architekturę zbudowaną w oparciu o bare-metal (bez host OS), trzy kontenery systemowe oraz Docker Engine.
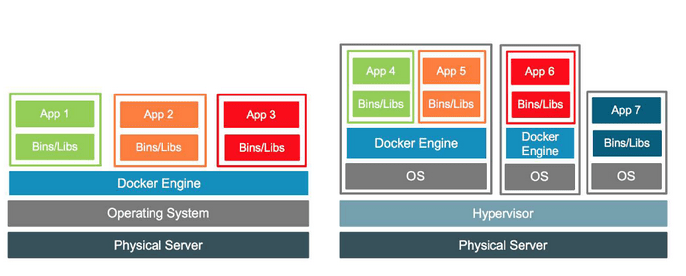
Rysunek 5 - przykład konteneryzacji oraz zagnieżdżonej wirtualizacji, źródło docker.com
Mikroserwisy i cloud native
Aplikacje w dzisiejszych czasach można kategoryzować i dzielić ze względu na różne technologie czy architektury wykonania. Jednym z najbardziej jaskrawych i znanych podziałów jest architektura monolityczna kontra mikroserwisowa. Ta druga jest mocno powiązana z kontenerami, gdzie aplikacja jest wdrożona na dziesiątki, a nawet setki czy tysiące kontenerów (Netflix posiada ponad 1000 mikroserwisów). Kontenerami zarządza orkiestrator oraz narzędzia platformy chmurowej na której taka aplikacja jest wdrożona. Takie aplikacje często nazywamy cloud-native ze względu na to, że były projektowane przy założeniu, że będą działać w chmurze. Przewidują więc awarie, działają oraz skalują się w niezawodny sposób, nawet gdy ich podstawowa infrastruktura napotyka na zakłócenia czy awarie.
Zasady dobrej konteneryzacji od Redhat
W celu wsparcia aplikacji cloud-native Redhat w 2017 roku zaproponował zasady dotyczące kontenerów aplikacyjnych, które można porównać choćby do zasad Solid w programowaniu obiektowym. Zasady brzmią następująco:
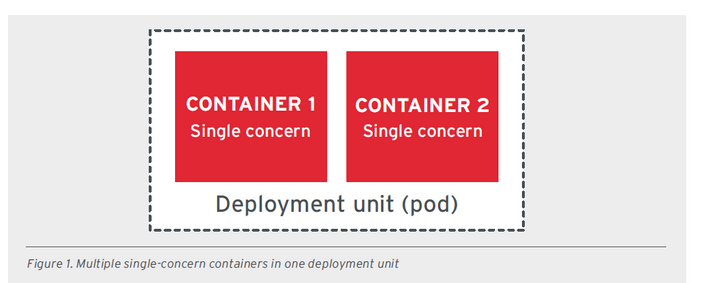
- SCP - SINGLE CONCERN PRINCIPLE - zasada ta mówi o tym, że każdy kontener powinien odnosić się do jednego problemu i robić to dobrze. Koncept jest podobny do zasady SRP z zasad SOLID. Jednak tutaj zamiast do pojedynczej odpowiedzialności klasy odnosimy się do kontenera, który powinien rozwiązywać konkretny problem i posiadać pojedynczy proces adresujący ten problem. Jeśli natomiast istnieje potrzeba zaadresowania różnych problemów w ramach pojedynczego serwisu, to istnieją specjalne wzorce konteneryzacji. Należą do nich sidecar czy init-containers, które pozwalają zorganizować taką pracę w ramach osobnych kontenerów na pojedynczej jednostce wdrożeniowej (podzie).
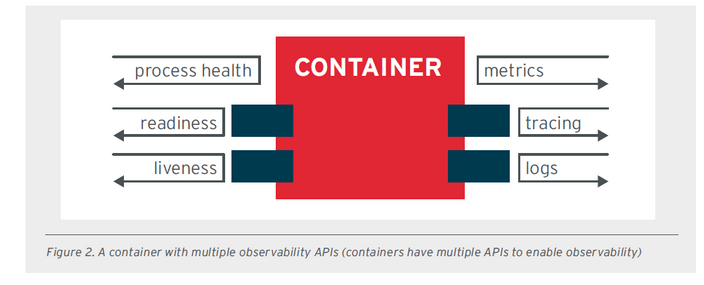
- HOP - HIGH OBSERVABILITY PRINCIPLE - ze względu na to, że kontenery są zarządzane przez orkiestratora np. Kubernetes to powinny udostępniać odpowiednie interfejsy API, dzięki którym platforma zarządzająca może sprawdzić stan danej aplikacji. Aplikacja powinna umożliwiać np. sprawdzanie żywotności (liveness) czy gotowości (readiness). Ważne zdarzenia w ramach aplikacji powinny być rejestrowane zarówno w standardowym strumieniu błędów (STDERR), jak i standardowym strumieniu wyjścia (STDOUT), umożliwiając agregację logów za pomocą narzędzi takich jak Fluentd i Logstash.
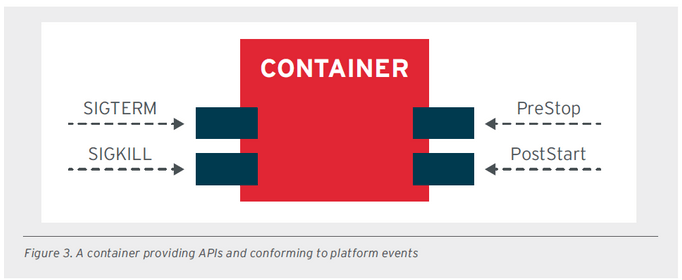
- LCP - LIFE-CYCLE CONFORMANCE PRINCIPLE - ta zasada nakazuje, aby aplikacja działająca w ramach platformy była w stanie reagować na polecenia tej platformy. Orkiestrator zarządza cyklem życia danego kontenera aplikacyjnego. Aplikacja powinna więc przechwytywać takie sygnały jak SIGTERM czy SIGKILL i zamykać aplikację w sposób kontrolowany (takie zamknięcie można zapisać do logów). Istnieją również inne zdarzenia, takie jak PostStart i PreStop, które mogą mieć znaczenie dla zarządzania cyklem życia danej aplikacji.
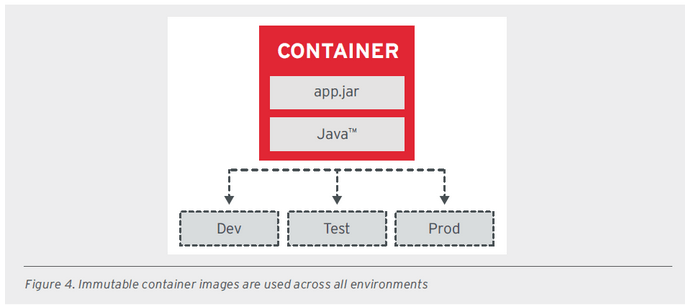
- IIP - IMAGE IMMUTABILITY PRINCIPLE - Kontenerowe aplikacje powinny być stałe i nie ulegać zmianom między różnymi środowiskami. Aby osiągnąć ten cel, zaleca się przechowywanie danych uruchomieniowych na zewnątrz oraz korzystanie z zewnętrznie skonfigurowanych ustawień. Zamiast tworzenia i modyfikowania kontenerów dla każdego środowiska, zaleca się stosowanie tych samych kontenerów i obrazów we wszystkich środowiskach. Wprowadzenie zmian w aplikacji w kontenerze powinno prowadzić do stworzenia nowego obrazu kontenera, który następnie będzie używany we wszystkich środowiskach.
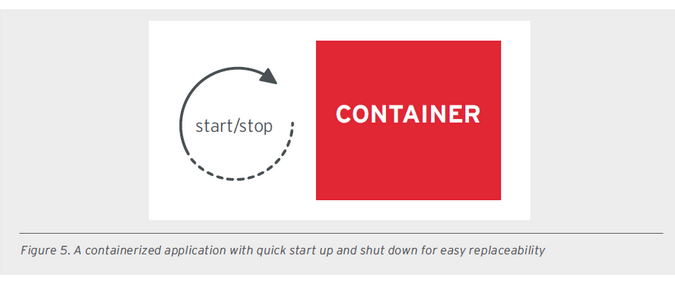
- PDP - PROCESS DISPOSABILITY PRINCIPLE PDP - Kontenery powinny być ulotne, efermalne i gotowe do wymiany w dowolnym momencie z różnych powodów, takich jak błędy health check, skalowanie w dół (ograniczanie zasobów), migracja na inny host. Aplikacje oparte na kontenerach powinny przechowywać swój stan na zewnątrz, być rozproszone i zapewniać nadmiarowość. Szybkie uruchamianie i zamykanie aplikacji jest kluczowe, nawet w przypadku nagłej awarii fizycznego sprzętu w centrum danych.
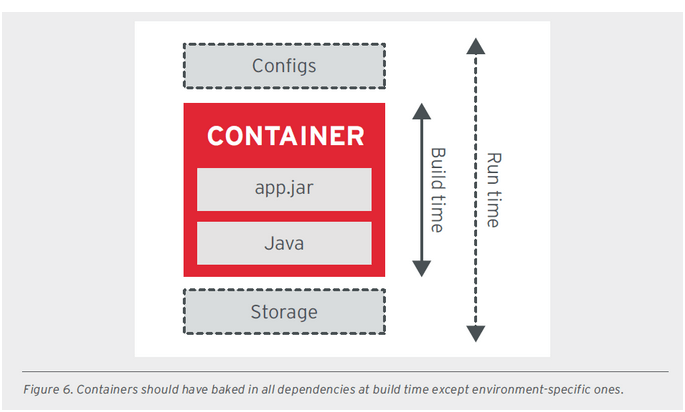
- S-CP - SELF-CONTAINMENT PRINCIPLE - zasada ta mówi, że kontener powinien zawierać wszystkie niezbędne składniki podczas budowy obrazu. Powinien także składać się z bazowego systemu opartego na jądrze Linux’a, zawierać zależności i biblioteki niezbędne do startu aplikacji. Wyjątkiem od tej zasady jest różnica w konfiguracjach np. zależnie od środowiska wdrożeniowego i muszą być dostarczane w czasie wykonania. Wtedy można do tego użyć mechanizmui Kubernetes ConfigMap.
- RUNTIME CONFINEMENT PRINCIPLE (RCP) - zasada ta zakłada, że każdy kontener powinien określać swoje potrzeby związane z zasobami i przekazywać je do platformy. Kontener powinien udostępniać profil zasobowy obejmujący parametry takie jak procesor, pamięć, sieć oraz wpływ na dysk. Te dane mają kluczowe znaczenie dla efektywnego planowania, automatycznego skalowania czy zarządzania. Jeśli jakiś kontener przekracza zaplanowaną ilość zasobów wtedy orkiestrator może podjąć odpowiednie działania jak np. skalowanie lub wyłączenie kontenera.
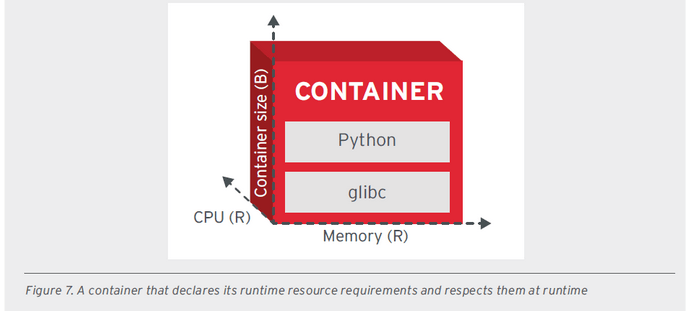
Wszystkie obrazki dotyczące dobrych zasad zostały zaczerpnięte z dokumentu udostępnionego przez firmę RedHat.
https://dzone.com/whitepapers/principles-of-container-based-application-design
Podsumowanie
Mamy nadzieję, że w tym wyczerpującym artykule udało nam się przybliżyć Wam tematy związane z konteneryzajcą oraz wirtualizacją. Zachęcamy do zapoznania się także z linkami ze źródeł, które w bardziej szczegółowy sposób tłumaczą omówienie w tym artykule zagadnienia. Jeśli zainteresowała Cię tematyka konteneryzacji polecamy naszą serię artykułów na temat Docker’a.
Źródła:
- https://www.how2shout.com/tools/8-free-best-open-source-bare-metal-hypervisors-foss.html
- https://vgyan.in/type-1-and-type-2-hypervisor/
- https://blog.nestybox.com/2019/09/13/system-containers.html
- https://www.docker.com/blog/containers-and-vms-together/
- https://www.blackmagicboxes.com/?p=349
- https://hemantjain.medium.com/7-design-principals-for-containers-a6135ef13182
- https://dzone.com/whitepapers/principles-of-container-based-application-design