FastAPI – czyli jak napisać proste REST API w Pythonie? – część 1
REST API w Pythonie? Nic prostszego. Zacznij z nami już dziś swoją przygodę z FastAPI!
 Autor:
Autor:W niniejszym artykule rozwijamy temat kompilacji, formatów plików, a także niskopoziomowych aspektów dotyczących języka assembly oraz architektury procesorów. Jeśli jesteście ciekawi, to zostańcie z nami.
Formaty plików binarnych
Formaty te definiują jak ma wyglądać struktura wykonywalnego pliku binarnego, obiektowego lub biblioteki. Jest on zależny od systemu w ramach jakiego kompilujemy dany program. ELF Format (Executable and Linkable Format) to format plików, popularny na systemach uniksowych (Unix, Linux). Można go poznać po rozszerzeniach: .bin,.o,.elf,.ko,.so albo braku rozszerzenia.
https://linuxhint.com/understanding_elf_file_format/
Najpopularniejszym formatem plików binarnych na Windowsie jest PE (Portable Executable). Jeśli chcecie się bliżej zapoznać z tym tematem to zapraszamy do odwiedzenia poniższych stron.
https://en.wikipedia.org/wiki/Portable_Executable
Zachęcamy do przeczytania porównania dla formatów wykonywalnych pod tym linkiem:
https://en.wikipedia.org/wiki/Comparison_of_executable_file_formats
Plik ELF
Plik ELF (Executable and Linkable Format) zasadniczo składa się z następujących elementów:
Każdy z tych elementów ma swoje miejsce i funkcję w strukturze pliku ELF, która pozwala na poprawne wczytanie, zarządzanie i wykonanie zawartości programu.
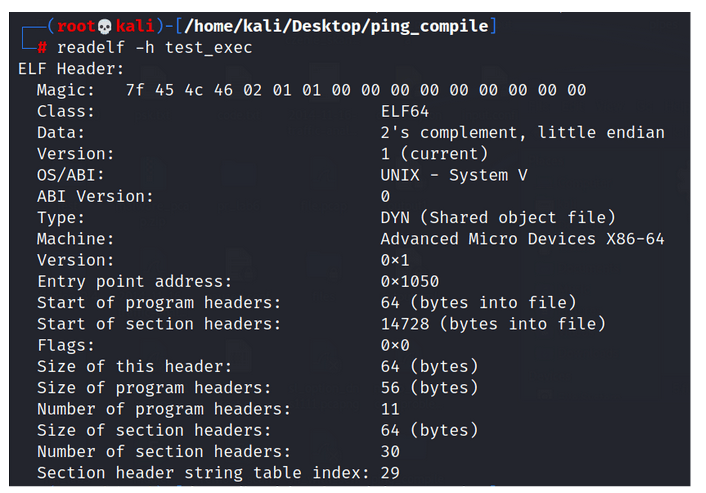
Rysunek 1 – Zawartość metadanych dla pliku wykonywalnego w formacie ELF.
Na rysunku możemy zaobserwować między innymi:
Magic bytes – Są to bajty na początku pliku ELF, które służą jako unikalny identyfikator. Są używane przez system operacyjny do rozpoznawania i odróżniania formatu ELF od innych formatów plików.
Class – Pole klasy określa architekturę systemu docelowego, czyli określa, czy plik ELF jest przeznaczony dla systemu 32-bitowego czy 64-bitowego. Dwie wspólne wartości dla tego pola to:
ELF32 (klasa 32): – Wskazuje na system 32-bitowy.
ELF64 (klasa 64): – Wskazuje na system 64-bitowy.
Data – To pole wskazuje, w jaki sposób dane binarne są uporządkowane w pamięci. Komputery mogą przechowywać dane wielobajtowe z najważniejszym bajtem (MSB) na początku (big-endian) lub najmniej znaczącym bajtem (LSB) na początku (little-endian)
Jeśli nie wiesz w jakim formacie jest zapisane, to próbując wykonać reverse engineering będziesz wywoływać złe adresy. W bibliotece pwntools przy czytaniu pliku elf można wyspecyfikować kodowanie.
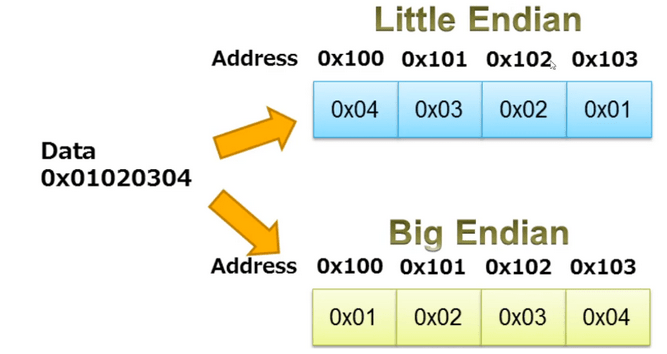
Rysunek 2 – Little vs Big endian, Dane zapisywane w odwrotnej kolejności w zależności od tego jak chcemy je zakodować, Źródło. iar.com.
Entry Point address – adres początkowy do wejścia do programu
Jeśli masz ochotę zgłębić wiedzę na temat tego jak dokładnie wyglądają dalsze sekcje formatu ELF, to możesz odwiedzić poniższego bloga.
Co się dzieje kiedy wykonujemy program?
Następują kolejne kroki:
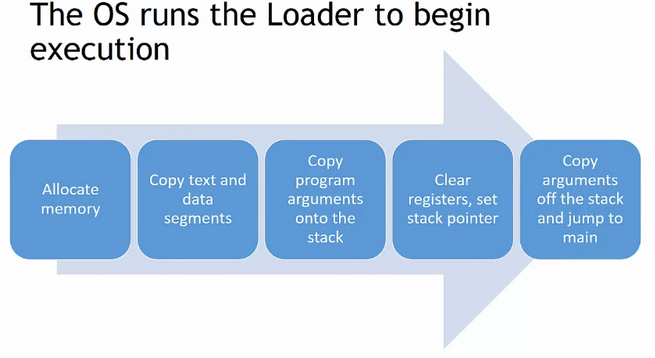
Rysunek 3 – Przedstawienie startu programu po jego uruchomieniu, Źródło: EngMicroLectures.
Procesor na najniższym poziomie komunikuje się z pamięcią, wykonuje operacje logiczne i przetwarza to na impulsy elektryczne. Jeśli procesor chce przetwarzać jakieś dane to operacji dokonuje w rejestrach, czyli bardzo szybkich komórkach pamięci znajdujących się wewnątrz procesora.
Jedynki i zera, które czytane są przez procesor powodują określone operacje na poziomie elektrycznym, które sprawiają, że określone obwody łączą się i wykonują operacje logiczne.
Wszelkie pętle, ify czy obiekty to tak naprawdę abstrakcyjne konstrukty, które pomagają ludziom.
Kody operacji, język assembly
Należy zrozumieć, że procesor w naszych komputerach ma do dyspozycji jedynie ograniczoną liczbę operacji matematycznych/logicznych reprezentowanych przez kod operacji -> https://pl.wikipedia.org/wiki/Kod_operacji
Komputery, jak już powiedzieliśmy rozumieją jedynie kod maszynowy. Jak więc ma się assembler do ciągu takich zer i jedynek jak na poniższym rysunku?

Rysunek 4 – zawartość pliku binarnego.
Otóż w języku assembly występują wspomniane wcześniej kody operacji. Są to liczby, będące fragmentem rozkazu przekazywanego do wykonania do procesora, które informują jaka operacja ma być wykonana. Każde polecenie asemblera jak add, sub, itd. posiada swój numer, na który jest zamieniane podczas kompilacji do kodu maszynowego. Zbiór kodów dla danego procesora jest określany w jego modelu programowym.
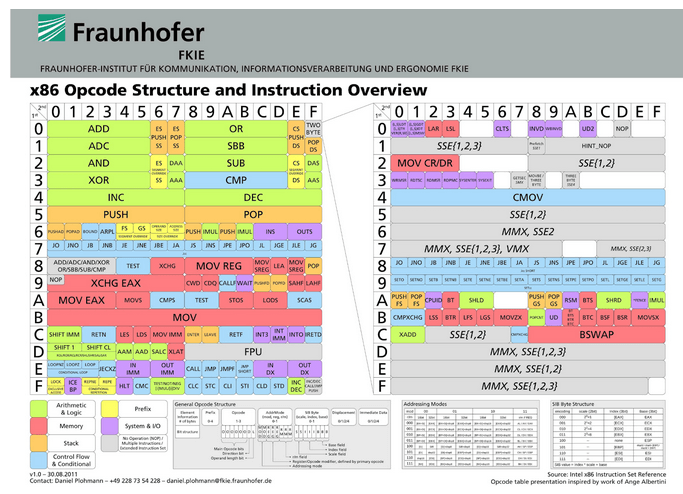
Rysunek 5 – Kody operacji dla architektury x86, Źródło Fraunhofer, FKIE.
Czym jest ISA?
Architektura zestawu instrukcji procesora (ang. instruction set architecture, ISA), model programowy procesora jest częścią abstrakcyjnego modelu komputera, który definiuje sposób sterowania procesorem przez oprogramowanie. ISA działa jako interfejs między sprzętem a oprogramowaniem, określając zarówno to, co procesor jest w stanie zrobić, jak i jak to zrobić.
ISA zapewnia jedyny sposób, w jaki użytkownik może komunikować się ze sprzętem.
Procesory posiadające ten sam model programowy są ze sobą kompatybilne, co oznacza, że mogą wykonywać te same programy i generować te same rezultaty. W początkowej historii procesorów model programowy procesora zależał od fizycznej implementacji procesora i niejednokrotnie całkowicie z niej wynikał. Obecnie tendencja jest odwrotna i stosuje się bardzo różne implementacje fizyczne (mikroarchitektury) pochodzące od różnych producentów, natomiast realizujące ten sam ISA. Czyli np. procesor AMD i Intel pomimo różnej fizycznej konstrukcji może mieć ten sam zestaw instrukcji – coś jak api niezależne od implementacji (fizycznej implementacji).
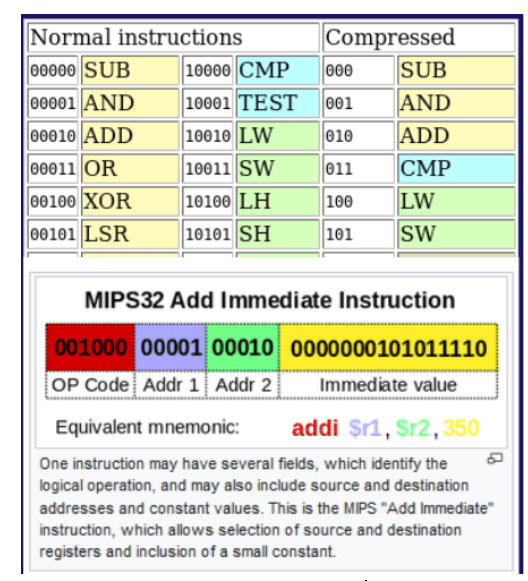
Rysunek 6 – kody operacji dla MIPS32, Źródło: wikipedia.
Podsumowując, istnieją różne typy języków assembly, które przeznaczone są do różnych architektur mających różne zestawy instrukcji. Program assembler tłumaczy język assembly na kod maszynowy danego procesora. Z tego wynika, że każda architektura CPU ma przynajmniej jeden assembler zdolny przetworzyć język assemblerowy na kod maszynowy tego procesora.
Oznacza to, że:
Jeśli chcesz poczytać więcej na ten temat, to zachęcamy do odwiedzenia poniższych linków:
Kompilacja – ciąg dalszy
Przypomnijmy na początku jak wygląda cały proces kompilacji za pomocą tego rysunku.
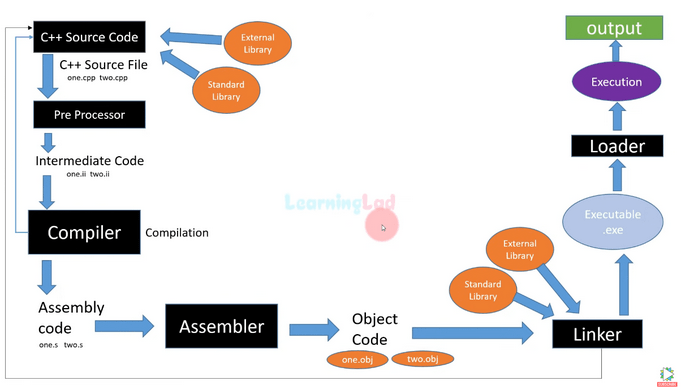
Rysunek 7 – proces kompilacji – Źródło: LearningLad.
Na początku kod źródłowy trafia do preprocesora, gdzie przyklejane są pliki nagłówkowe, a stałe rozwiązywane są na wartości. Następnie kompilator zmienia kod źródłowy w kod języka assembly. Kolejno assembler (program kompilujący język assembly do formatu binarnego) produkuje pliki obiektowe (.obj, .o). Na sam koniec linker rozwiązuje zależności poszczególnych plików i łączy wszystko w jeden plik binarny.
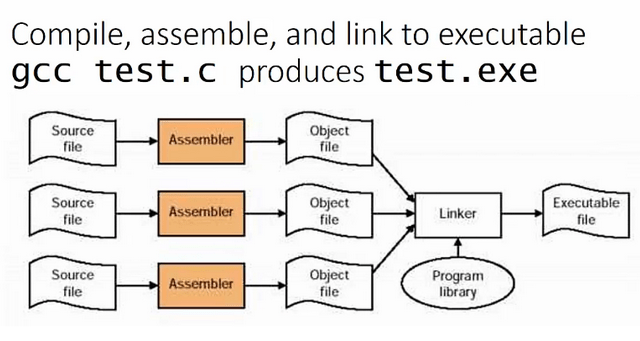
Rysunek 8 – kompilacja wielu plików naraz, Źródło: EngMicroLectures.
Możemy robić programy składające się z wielu plików i rekompilować tylko te, które zmieniamy, a nie cały utworzony projekt.
Analiza syntaktyczna, leksykalna i semantyczna
Warto również wspomnieć, że powyższe rysunku absolutnie nie wyczerpują tematu, ponieważ pomijają zarówno etap parsowania kodu źródłowego, jak i jego optymalizacje. Początkowe etapy wyglądają dokładniej opisując w następujący sposób:
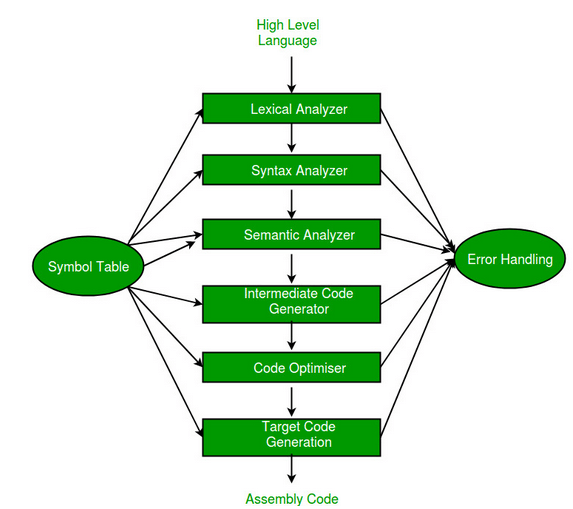
Rysunek 9 – Początkowe stadium kompilacji kodu źródłowego do assembly.
Kompilator na start dokonuje analizy leksykalnej (znajduje tokeny), a następnie usuwa white spaces. Można o tym myśleć w uproszczeniu jak o znajdowaniu wyrazów w zdaniu. Analiza syntaktyczna to inaczej parsowanie, czyli analiza ciągu znaków w języku naturalnym lub języku programowania zgodnie z zasadami przyjętej gramatyki formalnej. Parsowanie danych polega na przetwarzaniu informacji, ich porządkowaniu i dostarczaniu gotowych danych. Analiza semantyczna używa tzw. syntax tree i symbol table, żeby sprawdzić, czy kod jest semantycznie poprawny. Sprawdza np. zgodność typów. Następnie może, choć nie musi występować optymalizacja kodu, która sprawia, że wykonuje się on szybciej i z pomocą mniejszej ilości instrukcji języka assembly.
Podsumowanie
Mamy nadzieję, że dzisiejszy wpis rozjaśnił Wam tematykę dotyczącą sposobu działania procesora oraz procesu kompilowania. W następnej części opowiemy o tym, czym właściwie jest interpreter i dlaczego znacząco różni się od klasycznego podejścia.
Źródła:

FastAPI – czyli jak napisać proste REST API w Pythonie? – część 1
REST API w Pythonie? Nic prostszego. Zacznij z nami już dziś swoją przygodę z FastAPI!
Programowanie
2024-07-18

Dockeryzacja frontendu – zrób to dobrze React.js + Vite
Zrób to dobrze! Gotowy poradnik do dockeryzacji React.js z Vite.
Programowanie
2024-07-04
Czym jest RPC, serializacja, komunikacja międzyprocesowa oraz jak wiąże się to z systemami rozproszonymi?
AdministracjaProgramowanie
2024-06-20