O procesach, protobuf i RPC
Hej, dzisiaj jako Innokrea opowiemy Wam trochę o tym czym jest RPC, serializacja, komunikacja międzyprocesowa oraz jak wiąże się to z systemami rozproszonymi. Jeśli nie czytaliście naszego artykułu o systemach rozproszonych, to zachęcamy.
Procesy, wątki i komunikacja
Jakiś czas temu w artykule o pisaniu własnego serwera wyjaśnialiśmy jak używać wątków w celu przyjmowania kolejnych połączeń od klientów. Dowiedzieliśmy się wtedy, że wątki, będące jedną z podstawowych jednostek wykonania na komputerze współdzielą pamięć procesu w ramach którego funkcjonują. Niektóre interpretery (jak np. CPython) nie pozwalają jednak na przetwarzanie danych równoległych ze względu na wewnętrzną ich implementacje (GIL). Wtedy, w celu zwielokrotnienia mocy obliczeniowej, zamiast podejścia wielowątkowego zastosować można podejście wieloprocesowe. Pojawia się tutaj jednak jeszcze jeden problem, ponieważ procesy nie posiadają współdzielonej pamięci – trzeba zastosować mechanizmy pozwalające na wymianę informacji pomiędzy nimi. System operacyjny jest w stanie zarządzać dostępem do zasobów dla procesów, ale to, jaki proces w jaki sposób komunikuje się z drugim, spoczywa na programiście. Rozróżniamy różne tryby komunikacji – między innymi: pamięć współdzielona (shared memory), przesyłanie komunikatów (message passing), potoki, potoki nazwane, kolejki czy RPC.
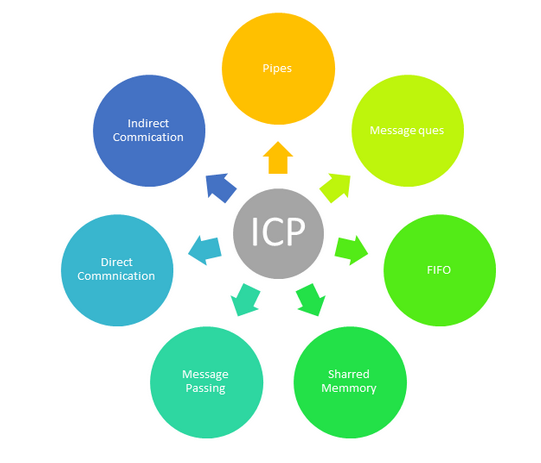
Rysunek 1 – typy komunikacji międzyprocesowej, źródło [1]
RPC
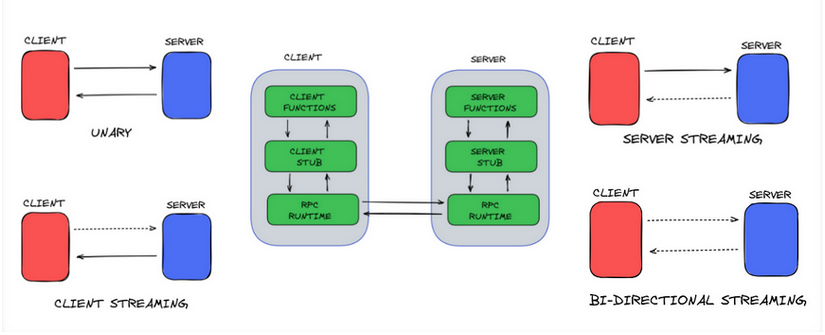
Implementując serwer w jednym z ostatnich artykułów wykorzystaliśmy do tego socket’y czyli jeden ze sposobów na komunikację międzyprocesową z wykorzystaniem sieci. Nie jest to jednak jedyny sposób na przekazywanie danych pomiędzy dwoma zdalnymi procesami. Mechanizm RPC (ang. remote procedure call) jest sposobem na zdjęcie z programisty odpowiedzialności za implementowanie przekazywania zdalnych wywołań. Programista jest w stanie wywoływać metody w ramach swojego programu prawie tak, jakby znajdowały się w tej samej klasie. Biblioteki wspierające RPC przetwarzają wywołaną metodę i upewniają się, że została ona wykonana po stronie drugiego procesu dokładnie raz.
Rysunek 2 – zdalne wywołanie procedury w architekturze klient serwer, źródło [2]
Komponentem odpowiedzialnym w RPC za ukrywanie całej logiki wywołania procedury przez sieć jest tzw. ‘stub’. Wewnętrzna implementacja RPC sprawia, że niezależnie od tego, w jakim języku programowania napisany jest drugi proces oraz jakie kodowanie wykorzystuje (big-endian vs little-endian), jesteśmy w stanie wywołać odpowiednią procedurę. W sposób ukryty RPC przeprowadza tzw. marshalling obiektu, który jest procesem bardzo podobnym do serializacji i pozwala na przetworzenie wywołania do formy możliwej do przekazania przez sieć. Po wywołaniu procedury na procesie docelowym wykonywany jest ten sam proces w drugą stronę (ang. unmarshalling), w celu zwrócenia wyniku wywołanej metody.
Jednym z najpopularniejszych frameworków używanych do RPC jest stworzony przez Google gRPC. Rozwiązane jest wspierane przez kilka języków, wspiera strumieniowanie danych i wykorzystuje tzw. protobuf do serializacji danych.
Protobuf
Czym jest protobuf? Jest to niezależny od używanego języka mechnizm do serializacji danych i definicji interfejsów. Tak zwane IDL (ang. interface definition language) sprawia, że możemy zdefiniować interfejs potrzebny do wywołania procedury niezależnie od języka, a następnie taki interfejs odpowiednio skompilować. O takim mechanizmie mówi się, że jest language-agnostic lub language-neutral. Dodatkowo, serializacja jest lepsza niż w takich formatach jak JSON/XML i powoduje, że wiadomości przesyłane pomiędzy procesami są mniejsze.
Przykład – protobuf + Java + gRPC
Spróbujmy odtworzyć przykład, który pokazywaliśmy w poprzednim artykule o socketach, gdzie wysyłaliśmy drugiemu procesowi liczby do sumowania. Przygotujemy projekt w środowisku IntelliJ w Javie z użyciem gradle.
Po pierwsze należy utworzyć nowy projekt w Intelij i stworzyć plik build.gradle, w którym zdefiniujemy nasze zależności. Powinien on wyglądać następująco:
plugins {
id "com.google.protobuf" version "0.9.4"
id "java"
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine'
implementation group: 'com.google.protobuf', name: 'protobuf-java', version: '0.9.4'
implementation group: 'io.grpc', name: 'grpc-all', version: '1.63.0'
implementation 'javax.annotation:javax.annotation-api:1.3.2'
}
sourceSets {
main {
java {
srcDirs 'build/generated/source/proto/main/grpc'
srcDirs 'build/generated/source/proto/main/java'
}
}
}
protobuf {
protoc {
artifact = 'com.google.protobuf:protoc:3.13.0'
}
plugins {
grpc {
artifact = 'io.grpc:protoc-gen-grpc-java:1.39.0'
}
}
generateProtoTasks {
all()*.plugins {
grpc {}
}
}
}
test {
useJUnitPlatform()
}
Po zapisaniu pliku powinien pojawić się przycisk ‘reload’, który należy kliknąć, aby pobrać zależności. Po pobraniu zależności należy utworzyć w katalogu src folder main a w nim folder proto, w którym zdefiniujemy nasze interfejsy i klasy modelowe.
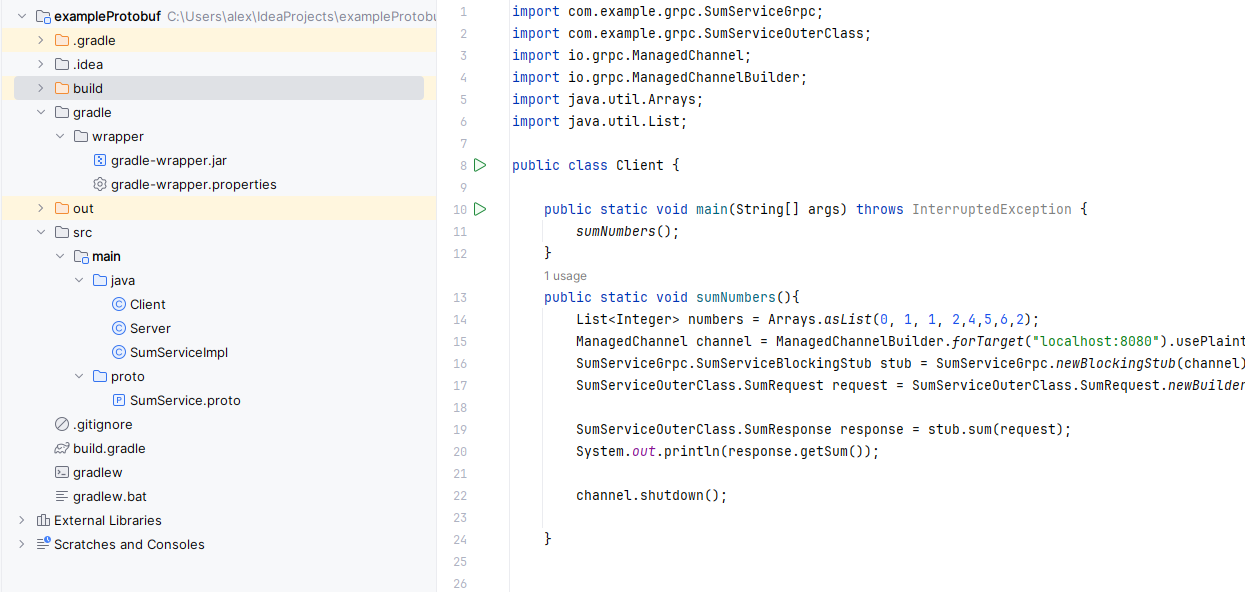
Rysunek 3 – Widok projektu
Przykładowa klasa proto może wyglądać następująco:
syntax = "proto3";
package com.example.grpc;
message SumRequest{
repeated int32 numbers = 1;
}
message SumResponse{
int32 sum = 1;
}
service SumService{
rpc sum(SumRequest) returns (SumResponse);
}
Teraz z użyciem menu po prawej stronie (Gradle) należy skompilować nasz plik proto w celu dostosowania implementacji do używanego języka.
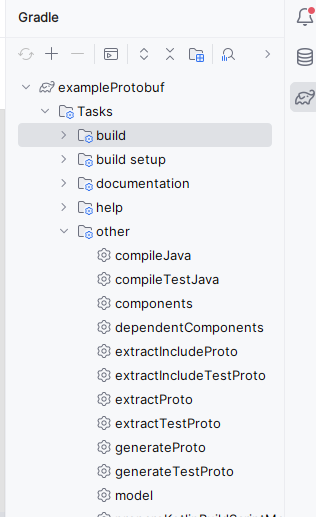
Rysunek 4 – Gradle menu
Po dwukrotnym kliknięciu generateProto nasza klasa powinna się skompilować, a efekty kompilacji powinny być widoczne w build\generated\source\proto\main\grpc\com\example\grpc. Efektem kompilacji powinna być między innymi klasa SumServiceImplBase z której skorzystamy pisząc nasz serwis do sumowania.
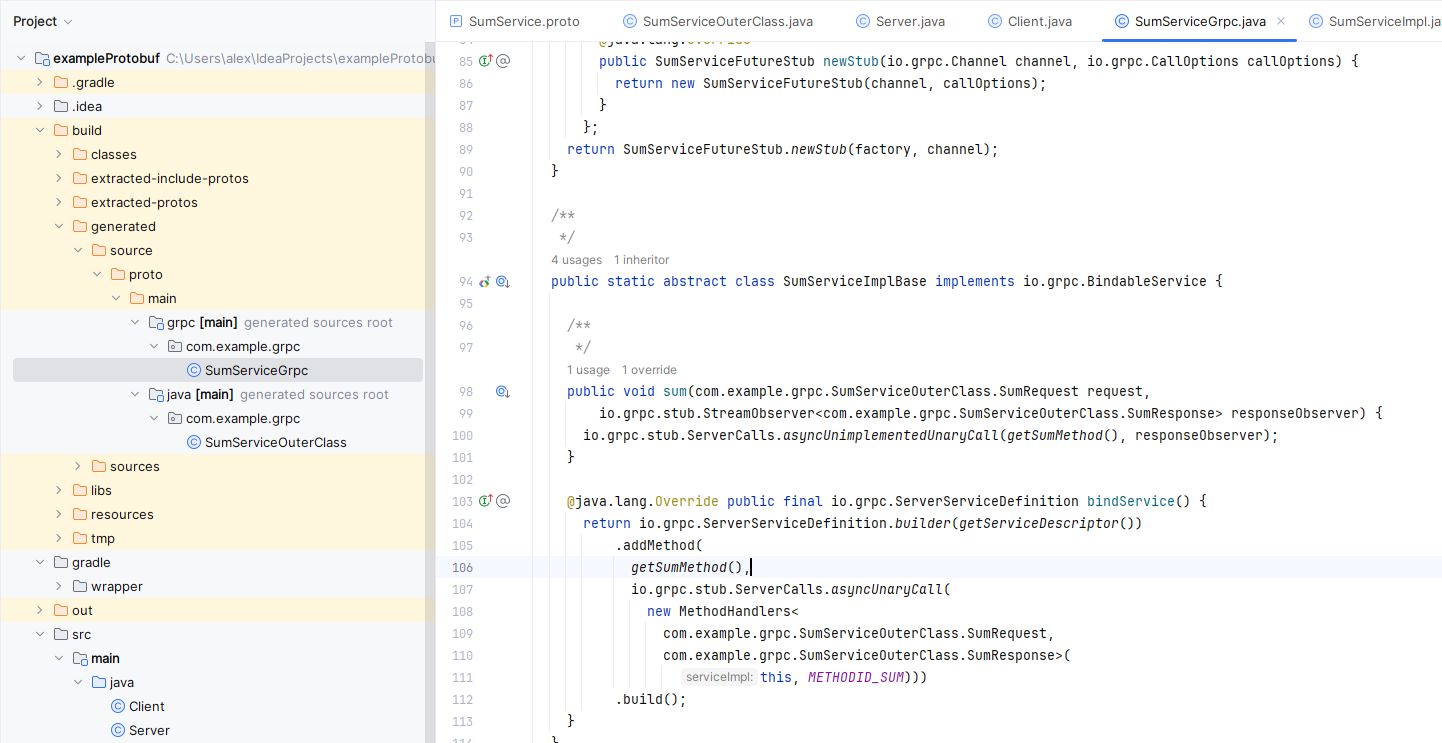
Rysunek 5 – Wygenerowana implementacja klasy bazowej ze zdefiniowanego pliku proto
Teraz w folderze main/java utworzymy plik SumServiceImpl i odziedziczymy wygenerowaną klasę SumServiceImlBase
import com.example.grpc.SumServiceGrpc.SumServiceImplBase;
import com.example.grpc.SumServiceOuterClass.SumResponse;
import io.grpc.stub.StreamObserver;
import com.example.grpc.SumServiceOuterClass.SumRequest;
import java.util.List;
public class SumServiceImpl extends SumServiceImplBase {
@Override
public void sum(SumRequest request, StreamObserver responseObserver) {
List numbers = request.getNumbersList();
Integer sum = numbers.stream().reduce(0, Integer::sum);
responseObserver.onNext(SumResponse.newBuilder().setSum(sum).build());
responseObserver.onCompleted();
}
}
Nadpisujemy metodę zdefiniowaną w pliku proto z użyciem dyrektywy @override, a następnie pobieramy przesłane liczby, dodajemy i zwracamy metodą onNext() i kończymy komunikację wywołując onCompleted().
Następnie utworzymy dwa pliki – plik serwera oraz plik klienta przesyłający liczby do serwera. Oba korzystają z napisanego przez nas serwisu.
Klasa serwera:
import io.grpc.ServerBuilder;
import java.io.IOException;
public class Server
{
public static void main( String[] args )
{
try {
io.grpc.Server server = ServerBuilder.forPort(8080).addService(new SumServiceImpl()).build();
server.start();
System.out.println("Server started!");
server.awaitTermination();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Klasa klienta:
numbers = Arrays.asList(0, 1, 1, 2,4,5,6,2); ManagedChannel channel = ManagedChannelBuilder.forTarget("localhost:8080").usePlaintext().build(); SumServiceGrpc.SumServiceBlockingStub stub = SumServiceGrpc.newBlockingStub(channel); SumServiceOuterClass.SumRequest request = SumServiceOuterClass.SumRequest.newBuilder().addAllNumbers(numbers).build(); SumServiceOuterClass.SumResponse response = stub.sum(request); System.out.println(response.getSum()); channel.shutdown(); } }
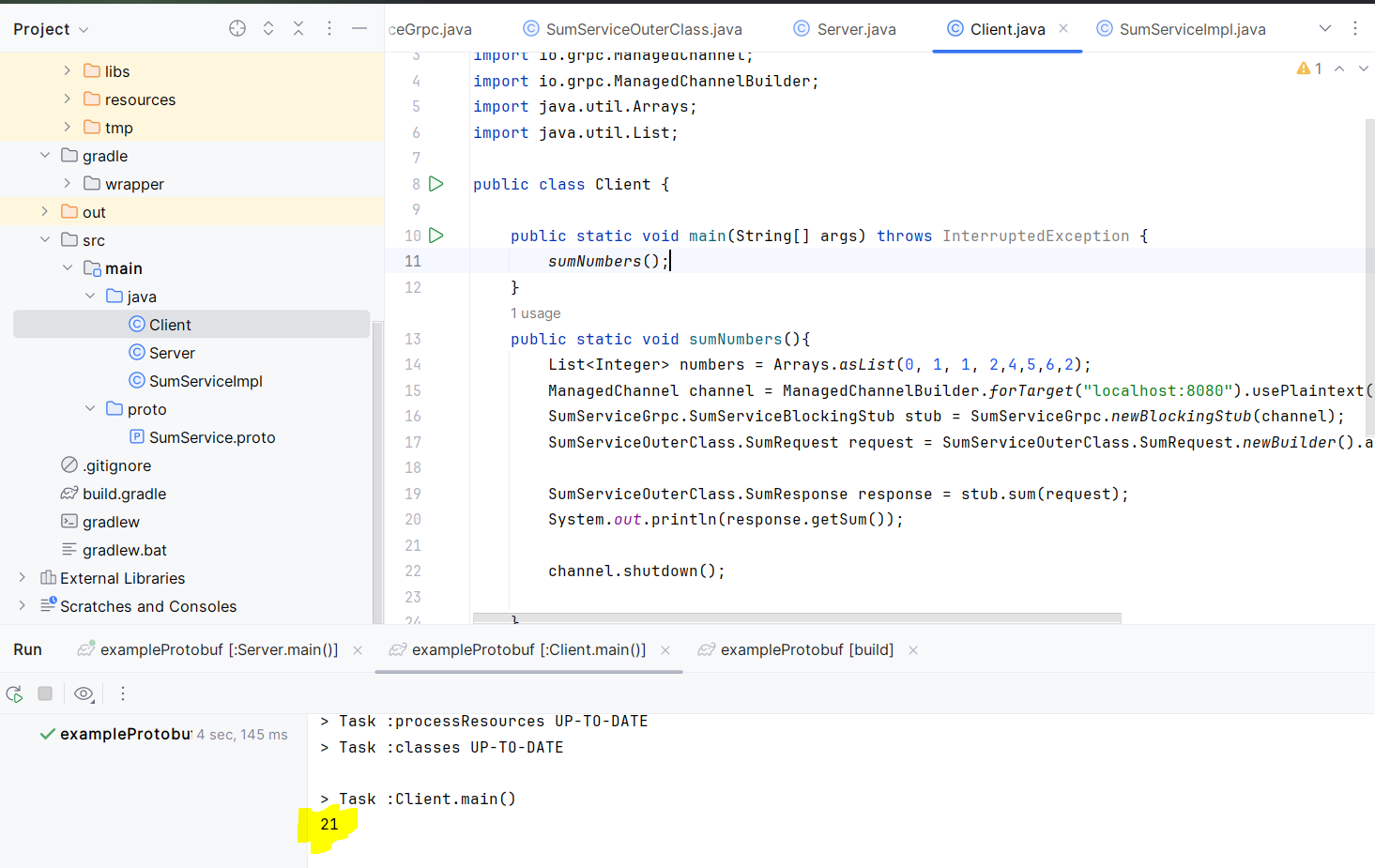
Rysunek 6 – Wynik uzyskany po stronie klienta po uruchomieniu serwera i klienta
Gdzie stosujemy gRPC?
Udało nam się skonstruować bardzo podstawowy projekt, dzięki któremu da się zademonstrować działanie gRPC w Javie. W jaki sposób jednak to rozwiązanie jest stosowane w programowaniu rozwiązań komercyjnych? Jakiś czas temu w naszym artykule dotyczącym systemów rozproszonych prezentowaliśmy różne architektury – w tym mikroserwisy. Część przykładów pokazywała tzw. event-driven architecture z zastosowaniem brokera. Nie jest to jednak jedyny sposób na realizację mikroserwisów. Architektura zorientowane na komunikację z użyciem gRPC jest szybsza i lżejsza jeśli chodzi o wielkość wiadomości (ze względu na serializację protobuf) w porównaniu choćby do JSON’a. Jeśli produkujesz aplikacje które są duże np. wielkości Netflixa, należy zastanowić się nad tym czy nie warto skorzystać z gRPC. Takie rozwiązanie może być szczególnie przydatne w aplikacji, która wymaga np. kolaboracji wielu użytkowników jednocześnie jak np. wspólna tablica na której piszą użytkownicy czy dokument jak w przypadku Google Docs.
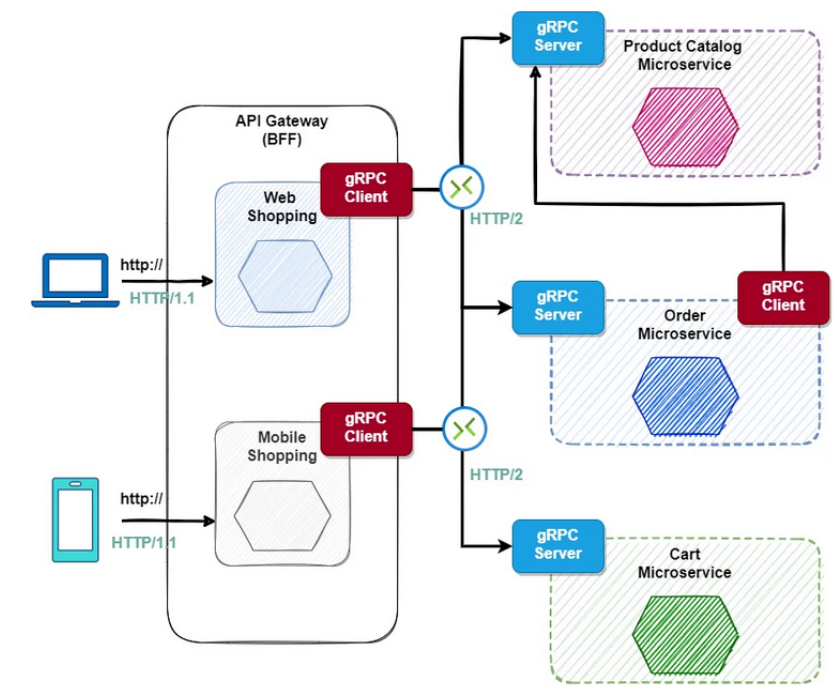
Rysunek 7 – Przykładowa architektura mikroserwisowa budowana w oparciu o gRPC, [3]
Podsumowanie
Udało nam się dzisiaj opowiedzieć o tym jak wygląda komunikacja międzyprocesowa, czym jest RPC oraz jak skonfigurować prosty projekt w Javie używający gRPC oraz protobuf. Jeśli jesteście chętni poczytać więcej o architekturach rozproszonych albo o socketach to polecamy nasze poprzednie artykuły. Do usłyszenia!
Źródła:
[1] https://www.guru99.com/inter-process-communication-ipc.html
[2] https://www.linkedin.com/pulse/remote-procedure-calls-rpc-umang-agarwal/
[3] https://techdozo.dev/grpc-for-microservices-communication/



