SOLID – czysty kod w programowaniu obiektowym

W poprzednim artykule mówiliśmy o podstawowych zasadach czystego kodu. Tym razem chcemy przedstawić Wam akronim SOLID, który jest zbiorem reguł dla programowania obiektowego, a którego stosowanie sprawia, że kod jest bezpieczniejszy i łatwiejszy w utrzymaniu. W tym artykule postaramy się omówić jego zasady.
Poszczególne litery akronimu SOLID oznaczają:
- SRP: The Single Responsibility Principle
- OCP: The Open-Closed Principle
- LSP: The Liskov Substitution Principle
- ISP: The Interface Segregation Principle
- DIP: The Dependency Inversion Principle
Przejdźmy od razu do zapoznania się z pierwszą zasadą.
SRP: The Single Responsibility Principle – zasada pojedynczej odpowiedzialności
Zasada ta mówi, że „Powinien istnieć tylko jeden powód do zmiany klasy”. Co to oznacza? Każda z klas powinna mieć konkretnie zdefiniowaną odpowiedzialność, zakres działania, jedno przeznaczenie. Lepiej, żeby klas było więcej, a ich funkcjonalności były rozdzielone niż by dochodziło do tworzenia klas „bogów”, które zajmują się obsługują wiele funkcjonalności na raz. Na przykład: Możemy mieć klasę o nazwie HardwareHandler, która zajmuje się odczytem z pliku informacji o sprzęcie komputerowym oraz jego zapisem do bazy danych. Jak widzimy na tym prostym przykładzie zasada pojedynczej odpowiedzialności została złamana. We właściwym scenariuszu klasę należałoby rozdzielić na dwie osobne: FileReader z odczytem informacji z pliku oraz HardwareRepository, która zajęłaby się zapisem informacji o sprzęcie do bazy danych.
Przykład jest trywialny, lecz pokazuje o co chodzi w zasadzie pojedynczej odpowiedzialności. Każda klasa ma swoje konkretne jedno przeznaczenie. Przy znacznie bardziej rozbudowanych aplikacjach brak zawężenia odpowiedzialności klas doprowadzi do zamętu, gdzie programistom, szczególnie tym, którzy nie są autorami kodu ciężko będzie zrozumieć klasy-molochy, a brak rozumienia działania programu może przełożyć się na wzrost liczby błędów i brak ich wykrycia.
Powyższy przykład nie oznacza jednak, że klasa może mieć tylko jedną metodę, by nie złamać zasady SRP. W przypadku klasy HardwareRepository moglibyśmy dodać tam metodę modyfikującą informacje o sprzęcie czy usuwającą dane z bazy i reguła ta zostałaby zachowana. Chodzi o to by klasa ta zachowała swoje jedno przeznaczenie. HardwareRepository będzie zajmować się działaniami związanymi z komunikacją z bazą danych w kontekście sprzętu komputerowego. Nie jest natomiast odpowiedzialna za odczyt czy zapis danych z pliku lub za przetwarzanie informacji, i o tym mówi SRP.
OCP: The Open-Closed Principle – zasada otwarte-zamknięte
Zasada ta mówi o tym, że nasz kod powinien być otwarty na rozbudowę, ale zamknięty na modyfikację. Oznacza to, że zmiany w aplikacji powinny odbywać się przez tworzenie nowego kodu, a nie zmianę już istniejącego. Jaka jest zaleta takiego podejścia? Oprócz czystości i zmniejszenia poziomu skomplikowania kodu zapewniona jest kompatybilność wsteczna systemu.
Brak zachowania zasady zamknięcia na modyfikację obrazuje prosty przykład biblioteki do naszego ulubionego języka, która ma wspomóc przetwarzanie danych w aplikacji. W nowej wersji autorzy do istniejących już metod zmienili liczbę przekazywanych parametrów. Skutek jest taki, że pobierając nową wersję biblioteki w naszym kodzie pojawią się błędy, które będzie trzeba poprawić by aplikacja znów mogła funkcjonować. Jak widać nie jest to najlepsze podejście do rozwijania oprogramowania i obrazuje brak kompatybilności wstecznej przy złamaniu zasady OCP.
Zasadę otwarcia na rozbudowę można ilustrować poniższym przykładem:
Mamy klasę Client, która korzysta z klas TextWriter i XmlWriter by zapisać dane do pliku o formacie txt i xml. TextWriter i XmlWriter są osobnymi niepowiązanymi klasami z metodą write(). Jeśli dodamy kolejny format, będziemy musieli w klasie Client dodać obsługę kolejnej klasy i co gorsza proces ten będzie powtarzany za każdym razem, gdy dodawane będzie nowe rozszerzenie. Nie jest to najlepsze rozwiązanie. Czy istnieje jakieś wyjście z tej sytuacji?
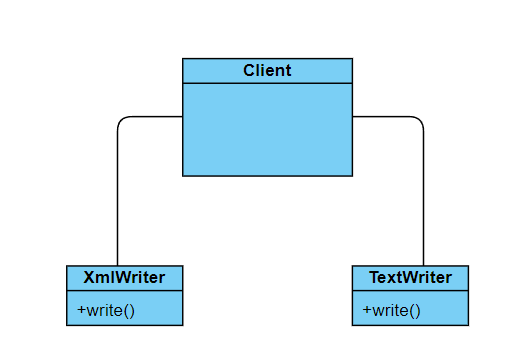
Rysunek 1: Przykład opisany powyżej.
W zasadzie OCP to abstrakcja jest kluczem. Jeśli utworzymy interfejs FileWriter z metodą write(), a następnie zaimplementujemy go w klasach TextWriter i XmlWriter, a na końcu zadeklarujemy by Client korzystał z tego interfejsu to będzie mógł swobodnie korzystać z każdej nowej implementacji interfejsu FileWriter. Tym samym nasz kod stanie się otwarty na rozbudowę (możliwość dodania obsługi kolejnych formatów) jednocześnie będąc zamkniętym na modyfikację (nie modyfikujemy działania klasy Client).
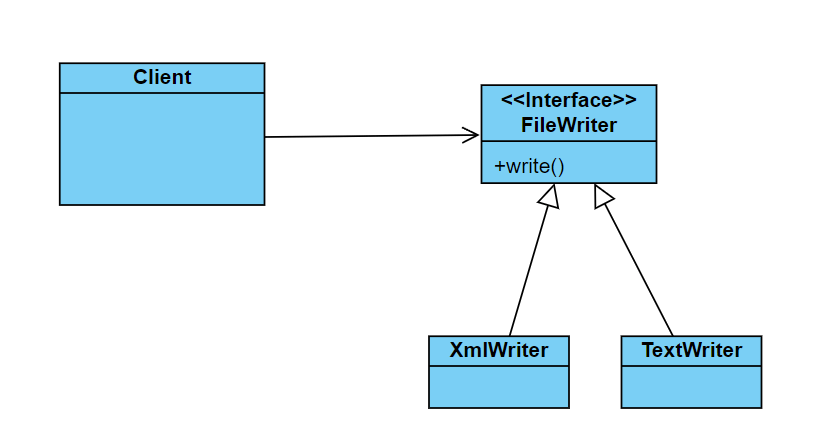
Rysunek 2: Wykorzystanie interfejsu by osiągnąć zasadę OCP.
LSP: The Liskov Substitution Principle – zasada podstawienia Liskov
Zasada ta została opracowana w 1988 roku przez Barbarę Liskov. Jej treść brzmi następująco: „Funkcje, które używają wskaźników lub referencji do klas bazowych, muszą być w stanie używać również obiektów klas dziedziczących po klasach bazowych, bez dokładnej znajomości tych obiektów”. Oznacza to, że jeśli tworzymy egzemplarz klasy potomnej, to niezależnie od tego, co znajdzie się we wskaźniku na zmienną, wywoływanie metody, którą pierwotnie zdefiniowano w klasie bazowej, powinno dać te same rezultaty. Zasada ta dotyczy więc poprawnego zaimplementowania dziedziczenia.
Przyjrzyjmy się przykładowi:
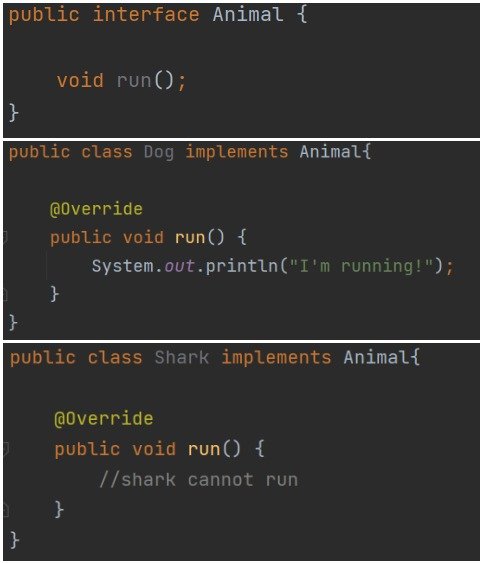
Rysunek 3: Interfejs Animal i jego implementacja w klasach.
Tworzymy interfejs Animal z metodą run(). Następnie implementujemy go w klasach Dog oraz Shark. I tu w tym nieco abstrakcyjnym przedstawieniu pojawia się problem. Pies może biegać, lecz rekin już nie. Implementacja metody run() dla rekina musiałby być inna. Musiałaby zmienić swój charakter względem klasy bazowej. Jednym z rozwiązań jest wejście na wyższy poziom abstrakcji i zmiana nazwy metody z run na move. Lepszym rozwiązaniem, jednak jest wyodrębnienie dwóch interfejsów. Przykład prezentujemy poniżej:
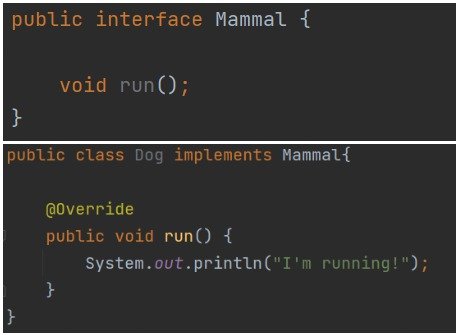
Rysunek 4: Interfejs Mammal i jego implementacja w klasie Dog

Rysunek 5: Interfejs Fish i jego implementacja w klasie Shark
Tworzymy interfejsy Mammal i Fish z metodami odpowiednio run() oraz swim(). Następnie implementujemy je do poszczególnych klas. Tym razem klasa Shark nie musi zmieniać zasady działania dziedziczonej metody. Zasada podstawienia Liskov została zachowana.
Dzięki stosowaniu LSP mamy pewność, że klasa pochodna nie zmienia niczego w działaniu klasy bazowej, a zarazem nasz kod jest precyzyjniejszy i czytelniejszy. Wymaga to natomiast przemyślenia struktury klas oraz ich dziedziczenia.
ISP: The Interface Segregation Principle – zasada segregacji interfejsów
Zasada ta mówi, że „Wiele dedykowanych interfejsów jest lepsze niż jeden ogólny”. Źle zaprojektowane interfejsy mają tendencję do rozrastania się przez co stają się one niespójne. Zasada ta zapewnia, że klasa nie będzie musiała implementować metod, z których nie będzie korzystać. Klasa nie będzie od nich zależna. Chodzi o tworzenie interfejsów bardziej sprecyzowanych, skupionych na pewnym obszarze działań. Przejdźmy do przykładu:
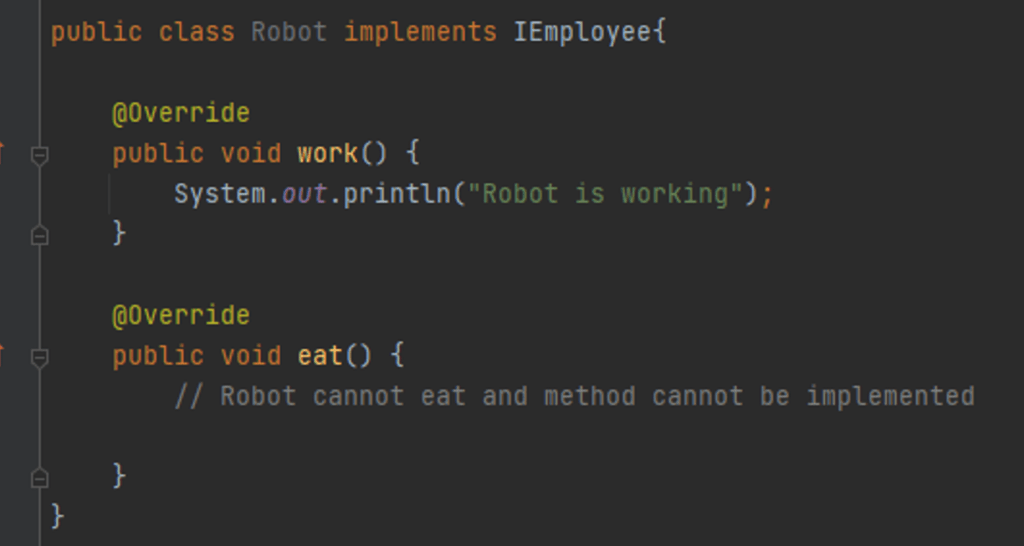
Rysunek 6: Klasa Robot implementuje interfejs IEmployee
Klasa Robot implementuje interfejs IEmployee dostarczając implementację dla metod work() i eat(). Druga metoda jest w tym przypadku zbędna, bo przecież robot nie może jeść. Rozwiązaniem jest utworzenie bardziej sprecyzowanych interfejsów i podzielenia odpowiedzialności.
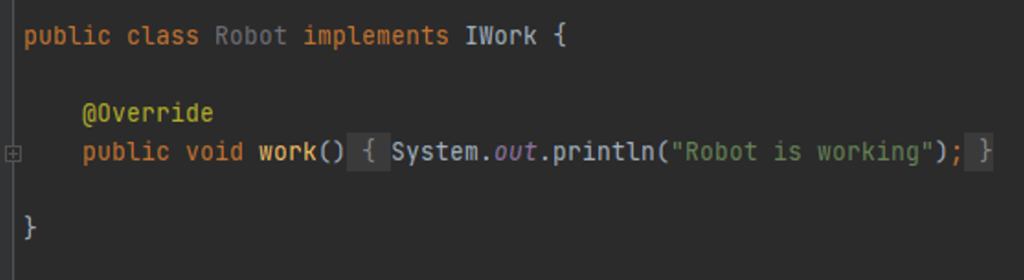
Rysunek 7: Klasa Robot implementuje bardziej szczegółowy interfejs IWork
Tworzymy interfejs IWork z metodą work(). Teraz klasa Robot korzystając z tego interfejsu nie jest zmuszona do implementacji żadnych niepotrzebnych jej metod. Interfejs ma jedną odpowiedzialność, a sam kod mimo, że przykład jest prosty, staje się bardziej przejrzysty i nie jest zaśmiecany przez niepotrzebne funkcjonalności.
DIP: The Dependency Inversion Principle – zasada odwrócenia zależności
Zasada ta mówi, że „Moduły wysokopoziomowe nie powinny zależeć od modułów niskopoziomowych. I jedne, i drugie powinny zależeć od abstrakcji. Abstrakcje nie powinny zależeć od szczegółów. To szczegóły powinny zależeć od abstrakcji”. Oznacza to, że tworząc nasze aplikacje powinniśmy dbać, aby moduły w nich zawarte zależały od abstrakcji a nie implementacji. Dzięki temu będziemy w stanie łatwiej wprowadzać zmiany w oprogramowaniu oraz ponownie wykorzystywać komponenty o czym możemy się przekonać z poniższego przykładu:
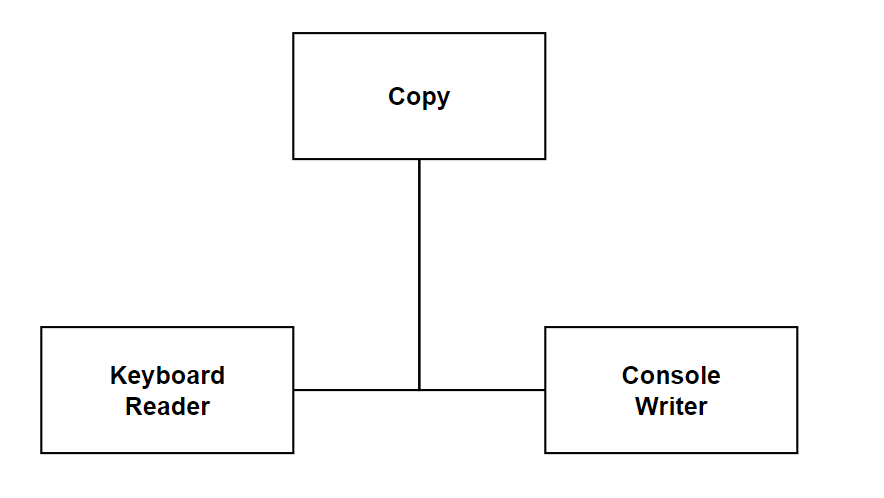
Rysunek 8: Diagram przedstawiający program do kopiowania znaków
Powyżej zaprezentowano schemat programu, który kopiuje znaki. W tym scenariuszu widzimy, że dane pobierane są z klawiatury za pomocą klasy Keyboard Reader, a następnie przekazywane do klasy Console Writer, która ma za zadanie wydrukować dane w konsoli. Jak widzimy obie klasy mogłyby być łatwo reużywalne w innych częściach programu. Inaczej jest z klasą Copy, która jest zależna od modułów niższego poziomu. Co jeśli chcielibyśmy by znaki zamiast w konsoli zapisywane były na dysku. Z pomocą przychodzi nam zasada DIP i wykorzystanie abstrakcji w postaci interfejsów.
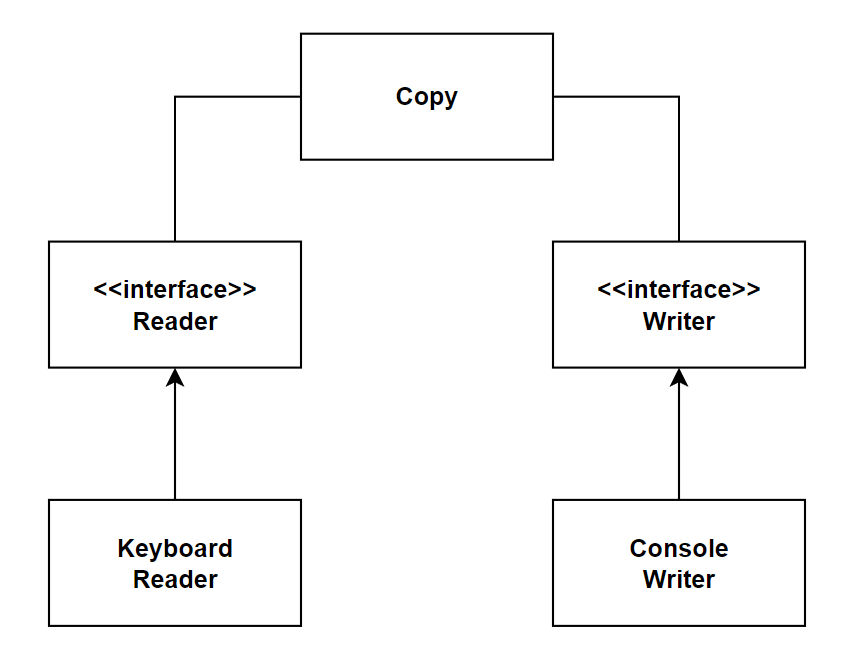
Rysunek 9: Dodanie abstrakcji w postaci interfejsu by zrealizować zasadę odwrócenia zależności
Moduł wysokopoziomowy zależy teraz od abstrakcji jaką jest interfejs, nie zaś od konkretniej implementacji. Dodanie nowego modułu do zapisu na dysku nie powinno być tym przypadku większym problemem.
Podsumowanie
Mamy nadzieję, że przez ten artykuł udało nam się nieco przybliżyć wam na czym polegają zasady SOLID i jak je stosować. Przykłady były inspirowane książką Agile Principles, Patterns, and Practices in C# autorstwa Roberta C. Martina i Micah Martin oraz poniższymi źródłami, więc jeśli jesteś zainteresowany pogłębieniem tematu polecamy tam zajrzeć.
Źródła:
https://www.baeldung.com/solid-principles