Clean code

W tym artykule, jako Innokrea chcemy opisać wam podstawy czystego kodu. Czysty kod, inaczej Clean code jest podejściem w programowaniu obiektowym, które zakłada stosowanie szeregu zasad dzięki, którym wytwarzany kod staje się bardziej przejrzysty, spójny i tym samym bezpieczniejszy. Dlaczego? Ponieważ programistom łatwiej jest na nim pracować, wychwytywać błędy czy po prostu rozumieć jego logikę.
Jakie są zalety podejścia Clean code?
Podstawową zaletą jest to, że będąc zaznajomionym z zasadami czystego kodowania stajemy się lepszymi programistami, a tym samym ułatwiamy pracę innym członkom zespołu czy firmy. Kolejnym bardzo ważnym argumentem jest to, że stosowanie tych zasad pozwala zapobiec sytuacji, gdy nasz kod jest tak niespójny, a jednocześnie tak źle zaprojektowany, że naprawa błędów jest znacznie bardziej czasochłonna, a czasem nawet niemożliwa w rozsądnym czasie. Kod, który nie jest klarowny i samo opisujący się potrafi dezorientować, powodować frustrację i wydłuża czas rozumienia logiki klas i ich naprawy oraz zwiększa awaryjność aplikacji. Złe podejście do architektury kodu sprawi, że po rozszerzeniu funkcjonalności lub ich zmianie na miejsce jednego błędu pojawią się trzy kolejne, które zmuszą programistów do dodatkowego nakładu pracy, by program działał. Można więc zauważyć, że dobre podejście do pisania kodu może znacznie oszczędzić nam czasu później oraz zwiększyć efektywność pracy nad rozwojem aplikacji w dłuższej perspektywie. Dobudowywanie kolejnych klas nad zły kod zwiększa nasz dług technologiczny, który pewnego dnia trzeba będzie zapłacić. Jakie są zatem podstawowe zasady czystego kodu?
Znaczące nazwy
Na początku zaczniemy od mogłoby się wydawać najprostszej, a jednocześnie jednej z podstawowych zasad pisania czystego kodu. Nazwy pełnią fundamentalną rolę w programowaniu. Nazywamy niemal wszystko od zmiennych, po klasy, funkcje, argumenty czy pliki. Dlatego warto się zastanowić jak w sposób schludny i przejrzysty podejść do nazewnictwa.
- Nazwy zmiennych, funkcji czy klas powinny przedstawiać intencje, powinny informować po co istnieją, do czego są wykorzystywane i co przechowują. Powinniśmy za wszelką cenę unikać nazw, które nie niosą ze sobą żadnych informacji. Ułatwi to pracę wszystkim osobom, które w przyszłości będą musiały korzystać z wytworzonego przez nas kodu.
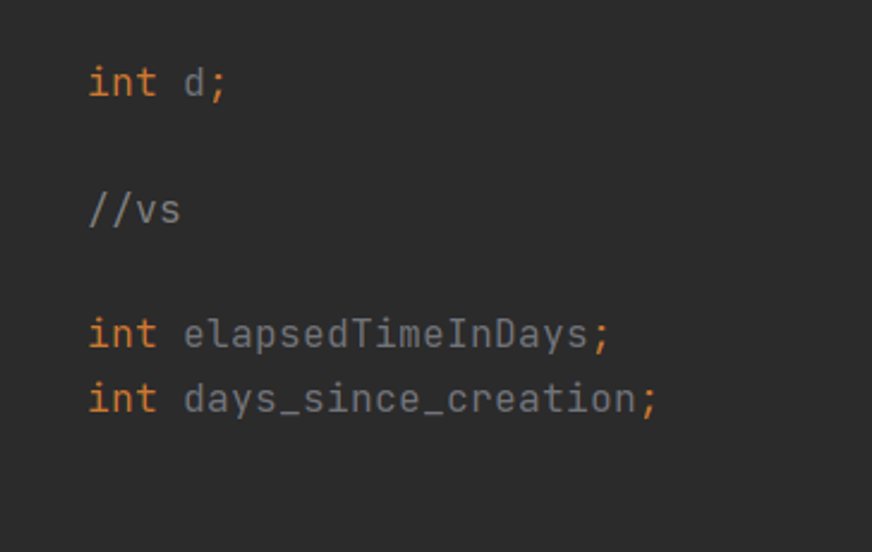
Rysunek 1: błędny sposób nazewnictwa vs poprawny sposób nazewnictwa
- Tworzone nazwy powinny dać się w prosty sposób wyszukać. Wiąże się to niejako z pierwszym podpunktem, gdzie bardzo złą praktyką są jednoliterowe nazwy zmiennych (wyjątkiem są na przykład krótkie pętle gdzie możemy posłużyć się jednoliterową zmienną jako indeksem), ale też używanie zbyt długich nazw, nazw-skrótów, które mogą być dla innych niejasne jak w przykładzie poniżej.
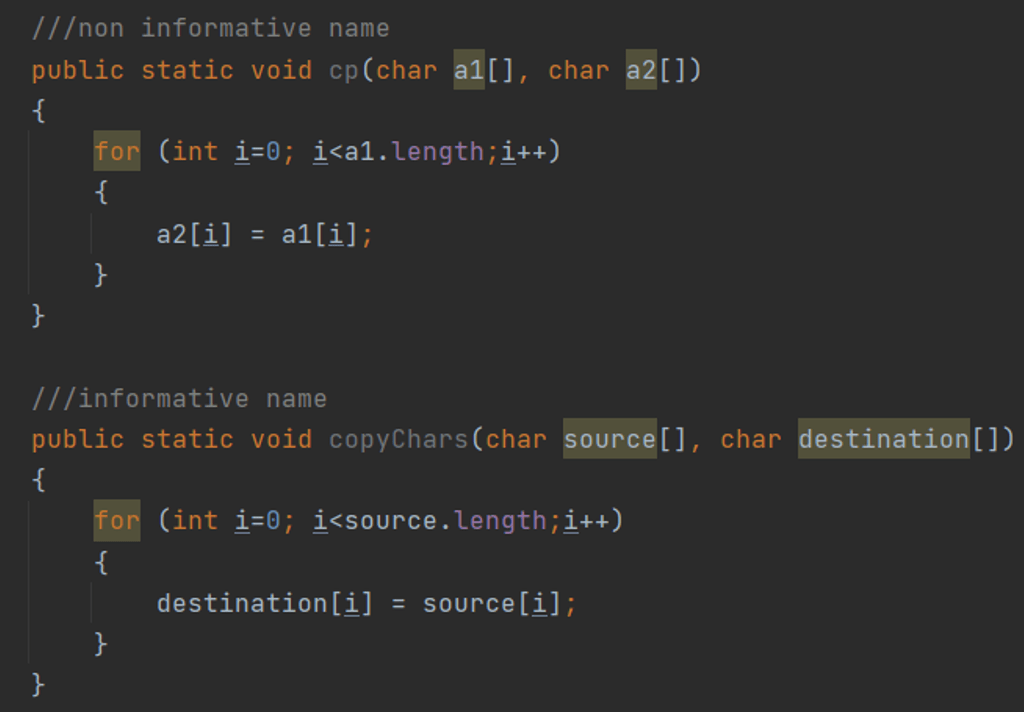
Rysunek 2: Zarówno nazwa jak i argumenty pierwszej funkcji nie są informatywne
- Należy być spójnym jeśli chodzi o nazywanie pojęć. Na przykład mylącym jest używanie słów fetch, retrieve i get dla analogicznych metod w różnych klasach. Podobnie używanie naprzemiennie Manager i Controller w nazwach klas. Prowadzi to do niejednoznaczności i sugeruje, że klasy zawierające te nazwy mają różne funkcjonalności.
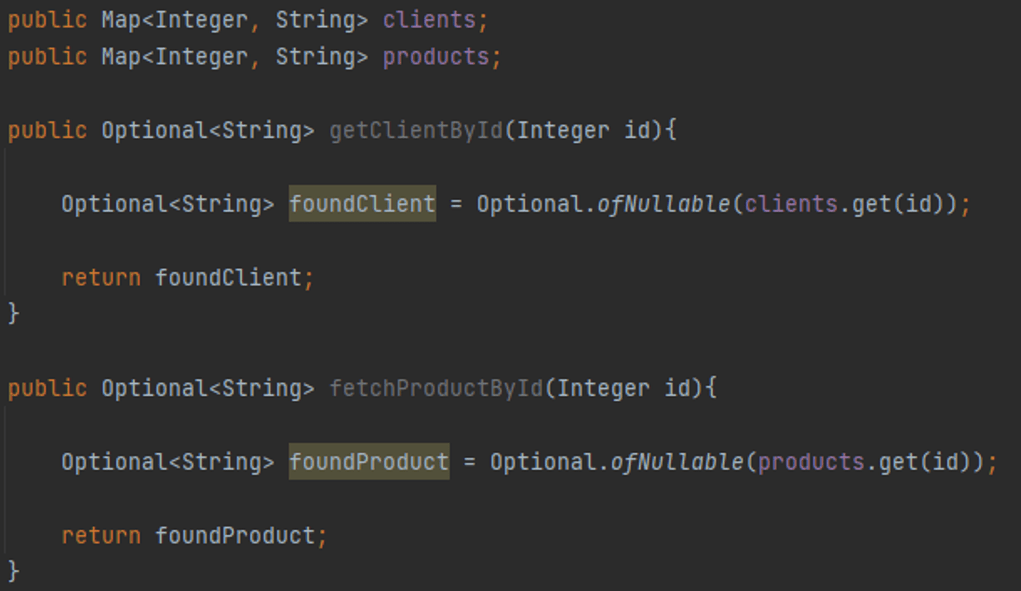
Rysunek 3: Przykład niespójności nazewnictwa metod w klasie
- Klasy i obiekty powinny być nazwane rzeczownikami lub w wyrażeniami rzeczownikowym jak na przykład: Customer, Account. Nie powinny natomiast zawierać czasowników.
- Funkcje natomiast powinny być określane czasownikami lub wyrażeniami czasownikowymi.
Funkcje
Ważnym aspektem tworzenia funkcji jest ich wielkość – muszą być one możliwie małe. Maksymalny rozmiar dobrze napisanej funkcji to około 20 linii. Powinna ona także wykonywać tylko jedna operację oraz działać na pojedynczym poziomie abstrakcji. To znaczy nie powinniśmy tworzyć funkcji, która na przykład jednocześnie wczytuje dane z pliku i wyświetla je w przeglądarce. Wykonywana jest tu więcej niż jedna operacja i nie został zachowany jeden poziom abstrakcji.
Dobrą praktyką jest również, żeby nasze funkcję umieszczać zgodnie z zasadą zstępującą, czyli tak, aby programista „czytając od góry do dołu” schodził w coraz niższe poziomy abstrakcji. Na przykład: mamy funkcję do tworzenia plików PDF, używa ona metod, które dodają meta dane do pliku oraz treść do dokumentu. Zgodnie z zasadą zstępującą najpierw umieszczamy funkcję główną a pod nią, te z których ona korzysta. Pozwala to utrzymać porządek poziomów abstrakcji oraz czytelność kodu.
Co do argumentów funkcji, maksymalna zalecana ich liczba to 2 lub 3 – im mniej tym lepiej. Funkcja jednoargumentowa jest łatwiejsza do zrozumienia niż funkcja wieloargumentowa. Ta druga jest jeszcze bardziej kłopotliwa, gdy dochodzi do testów jednostkowych, gdzie napisanie wszystkich scenariuszy testowych dla argumentów może być kłopotliwe. Podobnie nie powinno wykorzystywać się argumentów znacznikowych, czyli takich, które warunkują działanie funkcji. Na przykład przekazany Boolean, który zależnie od swojej wartości zmienia jakie operacje będą wykonywane. Jest to sygnał, że funkcję warto rozdzielić na co najmniej dwie pomniejsze funkcje, tak by każda z nich wykonywała osobną czynność. Na koniec warto też wspomnieć, że nazwy funkcji powinny pełnić rolę komentarza opisującego przeznaczenie funkcji.
Komentarze
Najpierw powiedzmy sobie jak nie powinno się używać komentarzy. Jedną z podstawowych zasad jest, że nie powinno komentować się złego kodu, a go poprawić. Istnieje tendencja do takiej praktyki co prowadzi do tego, że z czasem komentarz „starzeje się” i wprowadzać może w błąd sugerując pewne rozwiązania. Lepszy jest precyzyjny i czytelny kod z małą liczbą komentarzy niż zabałaganiony z mnóstwem komentarzy. Podobnie, jeśli nasze funkcje i zmienne wymagają opisywania ich oznacza to, że zrobiliśmy coś źle w temacie pierwszego punktu poruszonego w tym artykule. Nazwy powinny być na tyle dokładne i ekspresywne, żeby wyrażać nasze zamiary bez użycia komentarzy.
Istnieją jednak przypadki gdzie użycie komentarza jest uzasadnione:
Komentarzami możemy opisać do czego dopasowany jest regex. Znacznie ułatwi to pracę nie tylko nam, ale też innym programistom.

Rysunek 4: Komentarz opisuje jaki format waliduje dany regex
Komentarzem możemy ostrzegać, że funkcja nie jest thread-safe lub jest deprecated

Rysunek 5: Komentarz sugeruje użycie innej funkcji
Można stosować komentarze „TODO” w celu pozostawienia informacji co jest do wykonania, lecz z jakiegoś powodu nie może to być zrobione w tym momencie. Pamiętaj, żeby nie używać tego typu komentarzy jako wymówki do pozostawienia złego kodu.
Formatowanie kodu
Na koniec przyjrzymy się zasadom formatowania. Przy pracy z kodem dobrze jest wybrać zbiór prostych zasad formatowania i stosować się do nich. Jeśli dołączamy do zespołu powinniśmy zastosować się do panującego stylu nie wprowadzając dodatkowego zamieszania. Warto też zapoznać się z dobrymi praktykami, które ma niemal każdy język czy technologia. Java na przykład rekomenduje zapis Camel Case gdzie nazwa funkcji będzie wyglądać następująco getUserByName(). Natomiast język Python proponuje Snake Case, gdzie tą samą nazwę funkcji zapiszemy get_user_by_name(). Sugerujemy zwrócić także uwagę na wcięcia w kodzie. Jeśli zagnieżdżamy jedną instrukcję w wewnątrz innej to powinniśmy zrobić wcięcie.
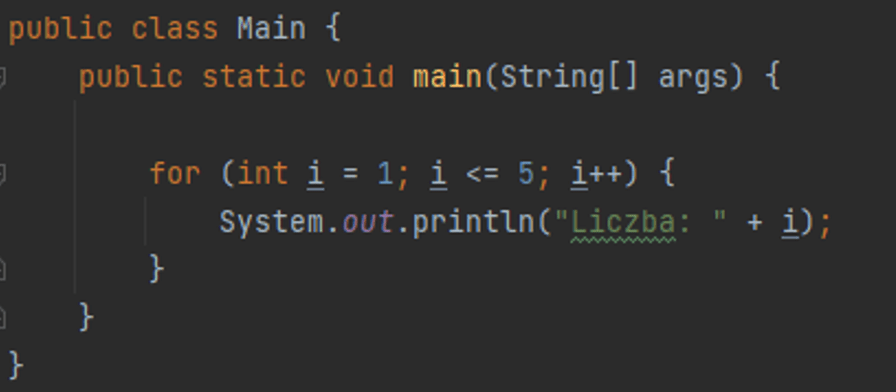
Rysunek 6: Zastosowanie wcięć w kodzie
Podsumowanie
Mamy nadzieję, że przedstawione przez nas podstawowe zasady zainspirują Cię do zmiany podejścia oraz skierują w stronę wytwarzania znacznie czystszego i przejrzystego kodu, który ułatwi pracę zarówno Tobie jak i innym. Jakość kodu i przejrzystość ma gigantyczne znaczenia dla jego bezpieczeństwa. Jeśli temat Cię zainteresował polecamy książkę Czysty kod autorstwa Roberta C. Martina oraz źródła poniżej. Pamiętaj, że bez praktyki doskonały kod sam się nie napisze!
Źródła:
https://garywoodfine.com/what-is-clean-code/
https://betterprogramming.pub/12-conventions-for-writing-clean-code-e16c51e3939a
https://www.pluralsight.com/blog/software-development/10-steps-to-clean-code
https://medium.com/swlh/the-must-know-clean-code-principles-1371a14a2e75