Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
 Autor:
Autor:W tym artykule opowiemy Wam trochę o tym czym jest kompilacja, a czym interpretacja kodu. Jakie są różnice, a jakie podobieństwa obu podejść? Jeśli masz ochotę poszerzyć swoje horyzonty, a dzięki temu być lepszym programistą, to zapraszamy do lektury.
Podstawowe pojęcia
Ze względu na duże zamieszanie w pojęciach w ramach tego tematu proponujemy na początku zapoznać się z definicjami, których treść zaczerpnęliśmy z Internetu. Dzięki temu będziemy mieli pewność, że pod tymi samymi pojęciami rozumiemy te same zjawiska.
Kompilacja
Najprościej mówiąc kompilacja jest procesem tłumaczenia języka programowania na inny język bądź kod maszynowy. Komputer nie potrafi zrozumieć samego języka programowania, który rozumie człowiek. Kompilator pełni więc rolę “tłumacza”, który jest w stanie wyprodukować plik w kodzie maszynowym, który jest rozumiany przez dany procesor wykonany w danej architekturze.

Rysunek 1 – Wysokopoziomowy obraz kompilacji (Źródło: EngMicroLectures).
Inaczej można powiedzieć, że są dwie wersje Twojego programu – ta którą rozumiesz Ty i nie rozumie jej komputer (source file np. “test.c”) oraz wersja w kodzie maszynowym, której nie rozumiesz Ty, ale rozumie ją komputer. Kompilator to więc “magiczny program”, który sprawia, że możemy tłumaczyć “human readable code” na “computer readable code”. Po uruchomieniu program ładowany jest z pamięci dyskowej do pamięci operacyjnej (RAM), a następnie wykonywany przez procesor.
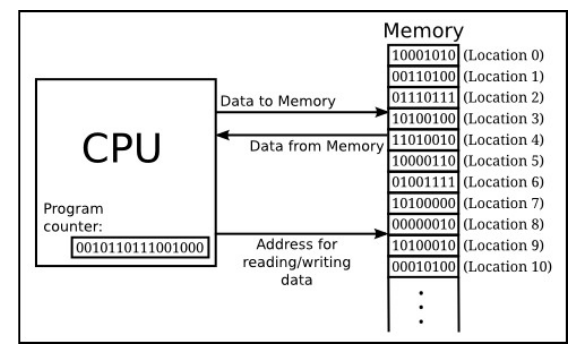
Rysunek 2 – Wykonanie programu na CPU, odczytanie instrukcji z pamięci komputera.
Czy na pewno jest to tak proste?
Oczywiście powyższe modele są znacznym uproszczeniem tego skomplikowanego tematu. Po wgłębieniu się w proces okazuje się, że ma on wiele kroków i jest bardziej skomplikowany, co widać na poniższym rysunku.
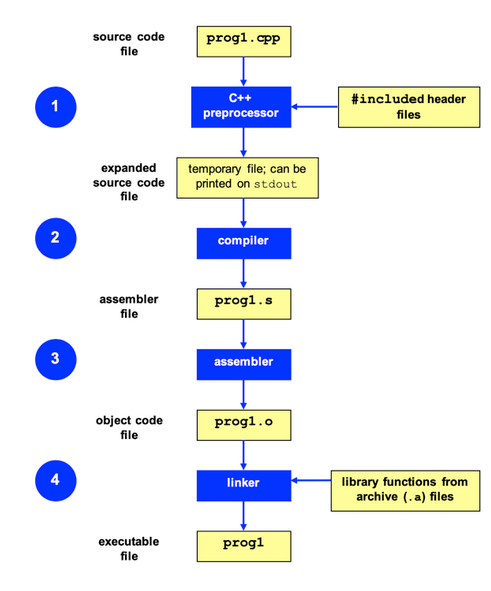
Rysunek 3 – bardziej szczegółowe przedstawienie kompilacji na podstawie języka C++, Źródło: Stackoverflow.
Preprocesor jest to program wchodzący w skład sterownika kompilacji, przetwarzający kod źródłowy według określonych reguł nazywanych dyrektywami, dając w rezultacie kod źródłowy gotowy do kompilacji. Standard C++ w pełni opisuje poprawną pracę preprocesora.
Mamy także kompilator, czyli program, który zamienia nam język wysokiego poziomu na kod assemblera dopasowany pod daną architekturę. Następnie wszelkie pliki zamieniają się na postać “object binary” (można o tym myśleć jak o stanie przejściowym między assemblerem a kodem maszynowym).
Na końcu powstaje executable, czyli plik binarny, który można uruchomić na danym systemie pod danym procesorem.
Przykład
Rozważmy poniższy przykład, aby oswoić się bliżej z praktycznym działaniem kompilatora. Wykorzystamy do tego język C i kompilator gcc w systemie Linux.
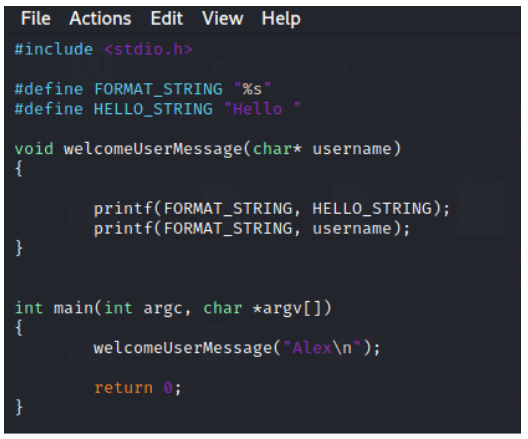
Rysunek 4 – Jest to prosty program napisany w C. Program korzysta z funkcji, dwóch stałych i argumentu, żeby wypisać “Hello Alex” na ekranie.
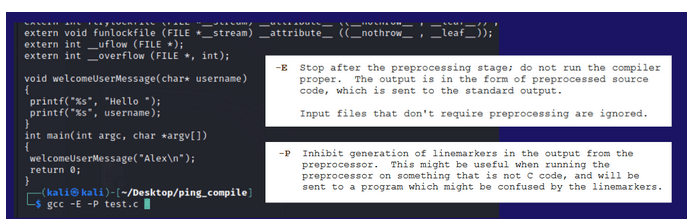
Rysunek 5 – Output preprocesora po wykonaniu instrukcji z przełącznikami -E i -P.
Zatrzymujemy po preprocesorze i widzimy stałe rozwiązane na konkretne wartości. Zmienne są bez zmian. Dodatkowo nagłówki funkcji są przeklejane do pliku dyrektywą #include <stdio.h>.
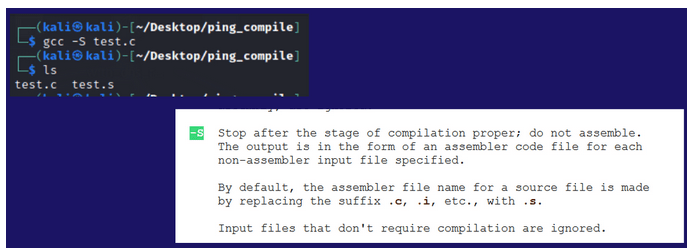
Rysunek 6 – Kompilacja do języka assembly.
Aby przejść do kolejnego kroku z pomocą kompilatora GCC skompilujmy nasz program do assemblera. Opcja -S w GCC powoduje utworzenie pliku assemblerowego.
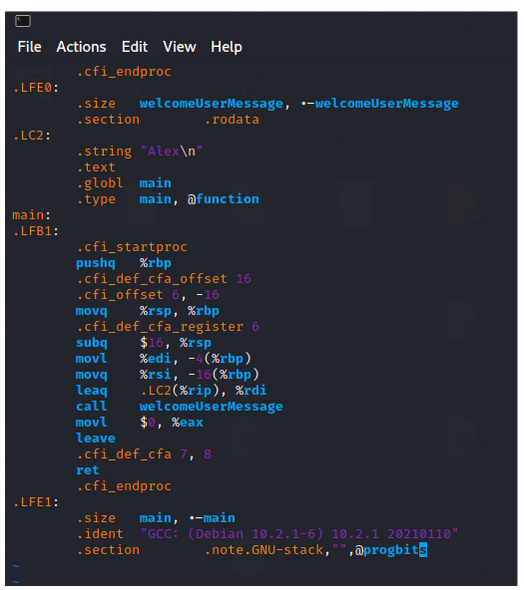
Rysunek 7 – Zawartość pliku test.s -> x86 assembler.
Skompilujmy “source C file” jeszcze raz do ASM (.s), podając nazwę pliku po parametrze “-o”. Następnie skompilujmy testASM.s do object file (test.o). Plik .o można więc skompilować zarówno z pliku assemblera jak i z pliku C z pomocą kompilatora GCC. Z pomocą opcji -c, przechodzimy krok dalej i kompilujemy nasz kod do pliku obiektowego “.o”.
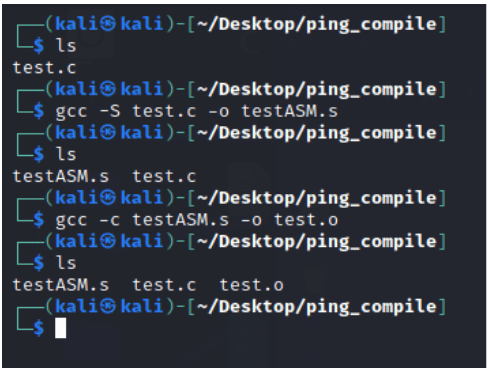
Rysunek 8 – kompilacja do języka assembly, a następnie do pliku obiektowego.
Rysunek 9 – Zawartość test.o – Tekst jest nieczytelny w zwykłym edytorze.
Wygenerowane pliki możemy podejrzeć z pomocą hexeditora. Tutaj plik “test.o”. Ma on 100 linii
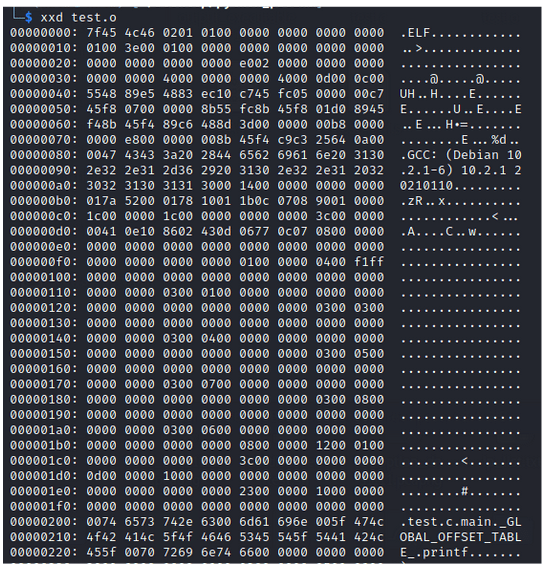
Rysunek 10 – plik obiektowy w edytorze heksadecymalnym.
Zlinkujmy teraz plik .o do pliku executable i spróbujmy uruchomić program. Linker rozwiązuje zależności poszczególnych plików i łączy wszystko w jeden plik wykonywalny.
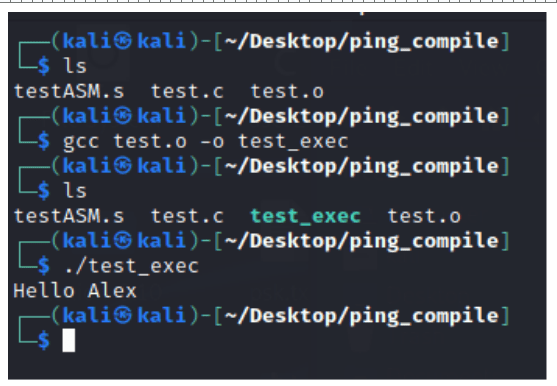
Rysunek 11 – koniec procesu kompilacji, uruchomienie programu.
Z pomocą edytora binarnego można zobaczyć, że plik wykonywalny, ze względu na dołączane zależności ma około 1000 linii, co jest znacząco większe od pliku obiektowego mającego ledwo 100 linii.
Podsumowanie
Mamy nadzieję, że udało się nam przestawić Wam w zrozumiały sposób jak działa kompilacja. Za tydzień będziemy kontynuować tematy niskopoziomowego działania programów a także formatów plików. Jeśli jesteście zainteresowani, to zapraszamy do lektury!
Źródła:

Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
AdministracjaInnowacja
Helm – czyli jak uprościć zarządzanie w Kubernetes?
Warto o tym wiedzieć! Czym jest Helm, jak go używać i jak ułatwia on korzystanie z klastra Kubernetes?
AdministracjaInnowacja

INNOKREA na Greentech Festival 2025® – zdobyliśmy zielone serce Berlina!
Jak wygląda przyszłość zielonych technologii i jak nasza platforma wpisuje się w ideę recommerce? Relacjonujemy nasz udział w Greentech Festival w Berlinie – zobaczcie, co przywieźliśmy z tego inspirującego wydarzenia!
WydarzeniaZielone IT