Kompilacja kontra interpretacja (cz. 3)

Dzisiaj będziemy kontynuować rozważania na temat kompilacji oraz interpretacji w językach programowania. Jeśli chcesz dowiedzieć się jakie wady mają języki kompilowane i jak na nowoczesne potrzeby odpowiadają interpretery to zapraszamy do lektury!
Problemy języków kompilowanych
Dlaczego w nowoczesnym świecie deweloperów języki kompilowane mogą powodować problemy? Jest to spowodowane między innymi:
- Czasem kompilacji – kompilowanie dużego projektu może trwać godziny ze względu m. in. na optymalizacje, które przeprowadza kompilator.
- Różnymi architekturami procesorów – kompilator generuje executable pod określoną architekturę, więc jest ciężej to dostarczać do klientów. Można to robić np. w postaci fat binary lub generować osobno pod każdą na jaką chcemy dystrybuować.
- Różnymi systemami – posiadają one różne formaty plików binarnych oraz inne syscalls. Więc jeśli chcesz dostarczyć oprogramowanie na każdy komputer, to Twój kod musi kompilować się na dowolnym komputerze z dowolną architekturą (np. ARM, x86, x64) z każdym systemem operacyjnym.
- Cykl deweloperski – zwykle wolniej wytwarzamy wtedy oprogramowanie
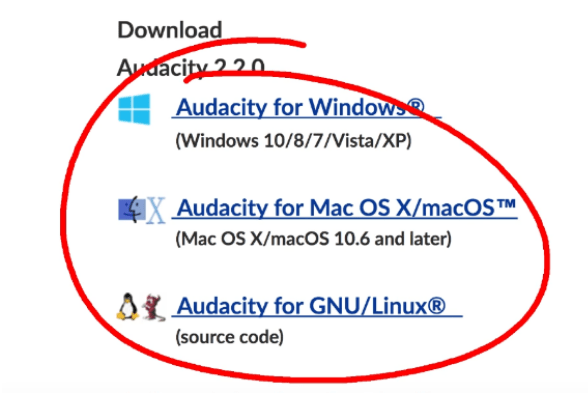
Rysunek 1 – przykład programu Audacity, który dostarcza różne instalatory na różne systemy operacyjne.
Proces Interpretacji
Czym właściwie jest interpreter? Zgodnie z definicją podaną na stronie Uniwersytetu Jagiellońskiego jest to “Program, który czyta i analizuje kod programu napisanego w jednym języku i na bieżąco go wykonuje”. Jest on kluczowym elementem znacznej części implementacji języków skryptowych oraz języków kompilowanych do kodu bajtowego.
Interpreter analizuje więc kod źródłowy programu, a przeanalizowane fragmenty od razu wykonuje. Realizowane jest to w inny sposób niż w procesie kompilacji, gdzie nie wykonuje się wejściowego programu (kodu źródłowego), a tłumaczy go do wykonywalnego kodu maszynowego lub kodu pośredniego, który jest następnie zapisywany do pliku. Dopiero po zapisie użytkownik jest w stanie uruchomić program.Wykonanie programu za pomocą interpretera jest wolniejsze, a do tego zajmuje więcej zasobów systemowych niż wykonanie kodu skompilowanego, lecz może zająć relatywnie mniej czasu niż kompilacja i uruchomienie. Jest to zwłaszcza ważne przy tworzeniu i testowaniu kodu, kiedy cykl edycja-interpretacja-debugowanie może często być znacznie krótszy niż cykl edycja-kompilacja-uruchomienie-debugowanie. Interpretacja kodu programu jest więc wolniejsza od uruchamiania skompilowanego kodu, ponieważ interpreter musi najpierw przeanalizować każde wyrażenie i dopiero na tej podstawie wykonać odpowiednie akcje, a kod skompilowany wykonuje wyłącznie akcje. W implementacjach będących w pełni interpreterami wielokrotne wykonanie tego samego fragmentu kodu wymaga wielokrotnej interpretacji tego samego tekstu.
Ze względu na to że języki interpretowane są dość proste w użyciu, to pomimo tego, że są mniej wydajne to warto ich używać. Wydajność Pythona polega na krótkim czasie developmentu aplikacji, co z biznesowego punktu widzenia często jest bardzo opłacalne i warto to robić kosztem wydajności aplikacji.
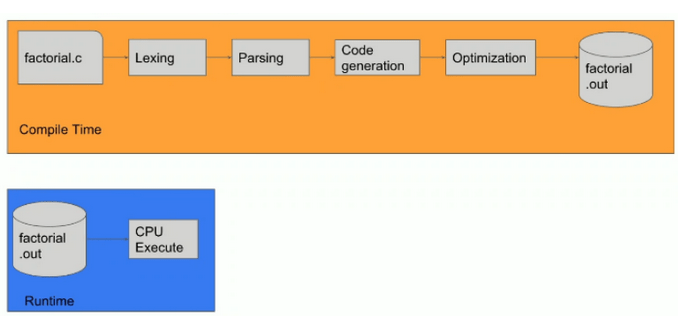
Rysunek 2 – Przebieg procesu kompilacji i uruchamiania (runtime) aplikacji skompilowanej, źródło: Omer Iqbal, GeekcampSG.
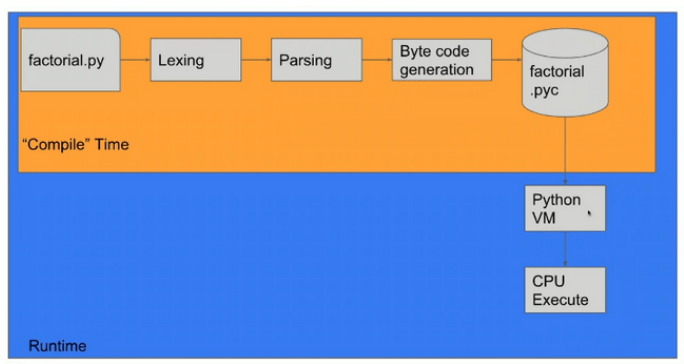
Rysunek 3 – Przebieg procesu interpretacji, źródło: Omer Iqbal, GeekcampSG.
Jak możemy zauważyć w procesie interpretacji wszystko następuje w runtime, czyli podczas uruchomienia aplikacji. Dlatego aplikacje języków interpretowanych są często wolniejsze niż te w językach kompilowanych.
Interpretacja na przykładzie Pythona i PVM
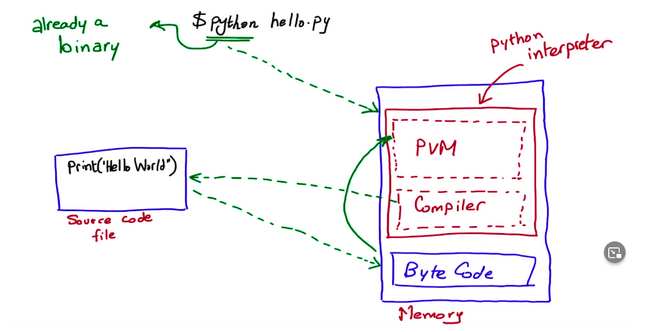
Większość ludzi pracujących w przemyśle informatycznym miała do czynienia z językiem Python. Jest on intuicyjny oraz ma bardzo niski próg wejścia. Czy zastanawialiście się jednak co dzieje się po wpisaniu polecenia python w terminal? Kiedy wpisujemy python3 lub python w nasz terminal, to tak naprawdę uruchamiamy plik binarny interpretera, który jest w całości ładowana do naszej pamięci operacyjnej. Python3 to tak naprawdę skompilowany program, a gdy piszemy “python3 abc.py”, to przekazujemy mu jako argument nasz kod.

Rysunek 4 – Uruchomienie interpretera języka Python.
Załadowany do pamięci program (interpreter) dzielimy na dwie sekcje: PVM (Python Virtual Machine) oraz kompilator. Ponieważ po słowie python hello.py podaje się plik pythonowy, to jest to argument tego programu. Kompilator będzie tłumaczył kod źródłowy języka python z file.py do tzw. bytecode (nie jest to kod maszynowy). Procesor nie rozumie bytecode, bo nie jest on tym samym co kod maszynowy wyprodukowany pod konkretny procesor w konkretnej architekturze. Bytecode jednak także składa się z zer i jedynek, bo jest plikiem binarnym. Bytecode jest interpretowany przez PVM, o której można myśleć jak o wirtualnym procesorze. Wirtualna maszyna (PVM) przyjmuje bytecode zamiast kodu maszynowego i dopiero wywołuje go na prawdziwym procesorze tłumacząc go na kod maszynowy Wygląda to w sposób przedstawiony poniżej.
Rysunek 5 – Przebieg interpretacji w języku Python, źródło: Afternerd YT.
Podsumowując, komponent PVM odpowiada za obsługę wszystkich platform na jakich dostępny jest interpreter poprzez tłumaczenie bytecode na kod maszynowy. Kompilator natomiast skupia się na tłumaczeniu kodu źródłowego na bytecode.
Przykład w języku Python
Przeprowadźmy teraz mały eksperyment jak to dokładnie wygląda jeśli chodzi o interpretację kodu w języku Python.
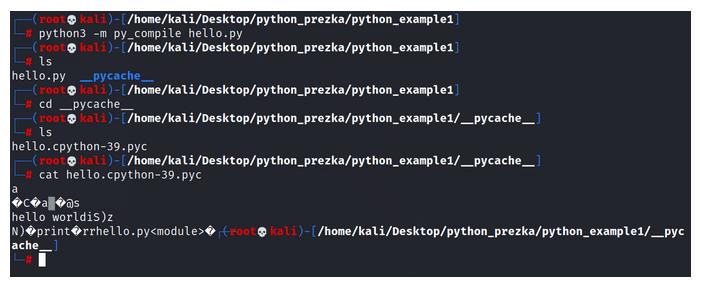
Rysunek 6 – Kompilacja do bytecode prostego programu Hello World.
Przeprowadźmy samą kompilację programu i wygenerujmy sam bytecode, który trafia do PVM. Widzimy utworzony folder __pycache__, a w nim plik o rozszerzeniu “.pyc” w którym jest nazwa interpretera “cPython”. Po wyświetleniu widać zaciemniony kod, bo jest to bytecode, czytelny dla PVM, ale nie do końca czytelny dla człowieka.
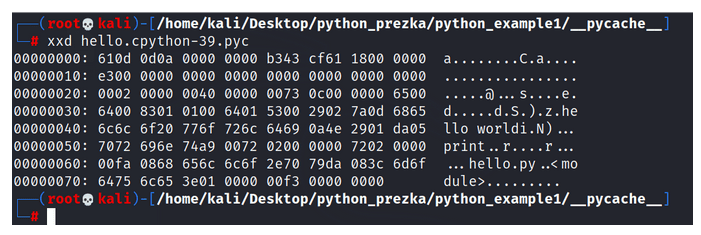
Rysunek 7 – bytecode wyświetlony jako plik binarny.
Po wpisaniu komendy “-m dis” na rysunku poniżej widzimy przetłumaczenie naszego bytecode na instrukcje bytecodeow’e w czytelnej dla człowieka formie. Jeśli bytecode to taki kod maszynowy dla PVM to, te instrukcje w czytelnej formie są jakby językiem assembly dla PVM (maszyny wirtualnej).
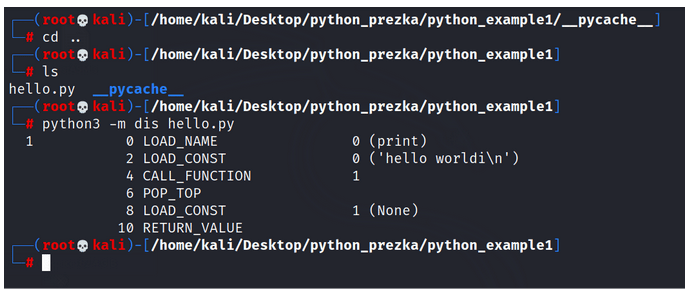
Rysunek 8 – instrukcje odczytane z bytecode.
Całość procesu interpretacji w Pythonie można przedstawić tak jak na obrazku poniżej.
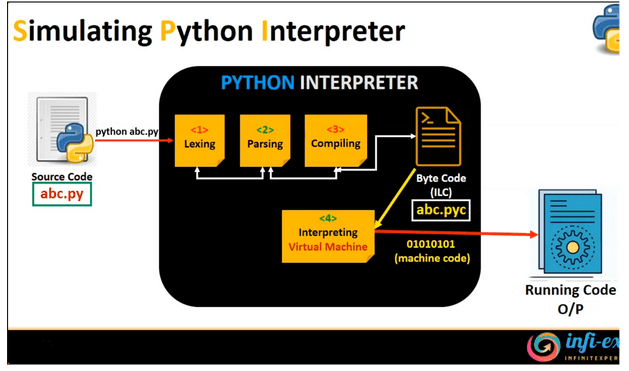
Rysunek 9 – Proces interpretacji, źródło: SNIPPET_MASTERY YT.
Podsumowując proces interpretacji składa się więc z następujących kroków:
- Załadowanie binarki interpretera pythonowego do pamięci operacyjnej.
- Podajemy jako argument nasz plik z kodem.
- Następuje “lexing” tj. analiza leksykalna potem parsowanie
- Następnie kod jest kompilowany do kodu pośredniego ILC (ang. intermediate language code) czyli bytecode’u (rozszerzenie .pyc).
- Maszyna wirtualna PVC interpretuje “byte code” wygenerowany przez kompilator i tłumaczy go na kod maszynowy, który jest wysyłany do procesora.
Kompilator w Pythonie jest wewnątrz interpretera, czyli inaczej niż np. w Javie.
Zalety i wady interpretacji
Oba podejścia tj. kompilacja jak i interpretacja mają swoje wady i zalety. Ewidentną zaletą języków interpretowanych jest to, że każdy kto ma interpreter może uruchomić program niezależnie od platformy. Interpreter do tego pisze się nieporównywalnie prościej niż kompilator. Proces interpretacji jest zwykle szybszy, niż kompilacji, bo nie optymalizuje kodu, choć program, który generuje interpreter działa mniej wydajnie niż ten kompilowany. Jeśli chodzi o wady, to warto powiedzieć, że interpreter ze względu na nadbudowaną abstrakcję generuje dużo więcej kodu. Dodawanie cyfry do zmiennej można reprezentować jedną instrukcją assemblera w językach kompilowanych, a w interpreterze przechodzi przez cały proces. Do tego porównując działanie w runtime (nie wliczając czasu kompilacji w językach kompilowanych) języki interpretowane działają znacznie wolniej.
Just-in-time compiler
Jeśli chodzi o znacząco obniżoną prędkość w runtime, to nowoczesne interpretery przychodzą nam z gotowym rozwiązaniem jakim jest JIT, czyli just-in-time compiler.
Kompilator Just-In-Time (JIT) jest składnikiem środowiska wykonawczego, który poprawia wydajność aplikacji w językach interpretowanych poprzez kompilowanie kodu bajtowego do natywnego kodu maszynowego w czasie wykonywania. Oznacza to mniej więcej tyle, że interpreter z JIT wykrywa tzw. “hot components” kodu (rzeczy powtarzalne i obciążające dla procesora) np. funkcje w pętlach, generuje z nich machine code, a następnie podmienia implementację i wykonuje program używając czystego machine code dla danego fragmentu kodu.
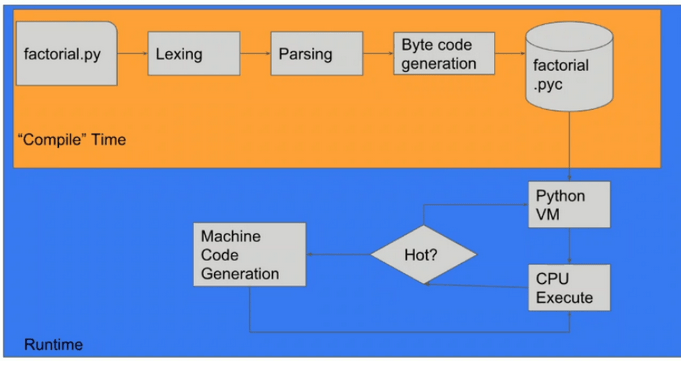
Rysunek 10 – Zastosowanie JIT w Pythonie, źródło: Omer Iqbal, GeekcampSG.
JIT używa także innych sposób optymalizacji takich jak:
- Constant Folding:
- Inline Caching
- Dead Code Elimination
- loop unrolling, loop fusion
Kiedy nie używać JIT?
Staramy się więc nie używać JIT dla mało powtarzalnych rzeczy i krótkich niewymagających obliczeń czy dla programowania webowego. Zawsze możemy zmierzyć czas wykonywania danej funkcji z JIT oraz bez JIT, żeby dowiedzieć się czy to się opłaca. Kod zoptymalizowany z użyciem JIT compiler może być nawet tysiące razy szybszy niż pierwotny kod. Istnieją interpretery, które mają wbudowany JIT compiler, oraz takie do których można doinstalować inny kompilator, który wspiera JIT. Kompilatorów jest wiele i nie wszystkie są przeznaczone pod wszystkie platformy. Przykładami kompilatorów, które wspierają JIT są: PyPy, Numba, Pyjion. Trzeba też sprawdzać jakiej wersji Pythona wymaga dany kompilator.
Podsumowanie
Podsumowując, można powiedzieć, że język interpretowany jest pisany z myślą o userze (programiście), a nie z myślą o komputerze, podczas gdy C czy Assembler odnoszą się bardziej niskopoziomowo do rzeczy wykonywanych na procesorze. W językach kompilowanych musimy poczekać dłużej na wygenerowanie naszego executable file, ale za to finalny program jest szybszy. Wadą jest zależność od systemu operacyjnego oraz architektury na której wykonujemy operacje. Możesz dostarczyć sam plik executable klientowi, więc kod jest “bardziej prywatny”. W językach interpretowanych klient wykonuje wysłany kod źródłowy na interpreterze, chyba że ktoś stosuje pewną obfuskację kodu, żeby utrudnić inżynierie odwrotną i chronić własność intelektualną np. PHP ioncube. Kod wykonuje się wolnej w samym runtime w porównaniu do języka kompilowanego. Interpreter jest niezależny od systemu operacyjnego i od architektury.
Wybór zależy więc od konkretnego przypadku oraz potrzeb biznesowych, czy trendów informatycznych. Mamy nadzieję, że wiedza z naszego bloga przyczyni się do lepszych decyzji w Waszych firmach.
Źródła:
- https://youtu.be/sQTOIkOMDIw
- https://youtu.be/BkHdmAhapws
- https://www.youtube.com/watch?v=VsjJfaUdFO8
- https://stackoverflow.com/questions/38516823/what-exactly-is-the-difference-between-intels-and-amds-isa-if-any
- https://www.quora.com/What-is-the-actual-difference-between-x86-ARM-and-MIPS-architectures
- https://towardsdatascience.com/how-does-python-work-6f21fd197888
- https://hackr.io/blog/python-interpreters
- https://en.wikipedia.org/wiki/Just-in-time_compilation



