Docker – zrób to dobrze i bezpiecznie cz. 1

Dzisiaj wracamy do tematu Dockera, tym razem od strony tematu dobrych praktyk. Jeśli jesteś już użytkownikiem zaznajomionym z oprogramowaniem Docker, to zachęcamy do lektury. Jeśli nie, to polecamy naszą serię w tym temacie.
Docker – dobre praktyki, czym są?
Zestaw dobrych praktyk dotyczy każdej małej i wielkiej dziedziny w informatyce i konteneryzacja czy wirtualizacja nie jest tu wyjątkiem. Zestawy najlepszych praktyk często nie mogą być w pełni wypełnione ze względu na ograniczony czas, wiedzę czy wymagania technologiczne, ale jest to pewien ideał do którego jako inżynierowie powinniśmy dążyć. Jeżeli chodzi o samą konteneryzację, to w 2017 zostały przez Redhat opublikowane zasady, które można porównać do zasad SOLID w programowaniu obiektowym. Jeśli chcecie bardziej wdrożyć się w ten temat, to zachęcamy do przeczytania tego artykułu na naszym blogu.
Wyjaśnia on nie tylko tajniki dobrej konteneryzacji, ale także to czym jest wirtualizacja i czym różni się od kontenerów aplikacyjnych czy systemowych. Dziś natomiast zajmiemy się bardziej specyficznymi poradami dotyczącymi konteneryzacji z użyciem Docker’a.
Używaj oficjalnych, sprawdzonych obrazów – jeśli używamy jakiegoś obrazu, warto sprawdzić, czy na pewno pochodzi on z dobrego źródła. Domyślnie Docker korzysta z dockerhub’a, gdzie wiele firm wrzuca obrazy swoich produktów jak np. node czy python. Na stronie samego Dockerhuba są specjalne filtry, które pozwalają odróżnić oficjalne obrazy, zweryfikowane oraz niezweryfikowane. Pewną wskazówkę może także sugerować ilość pobrań, ale oznaczenie samych twórców Dockerhub jest tutaj decydujące.
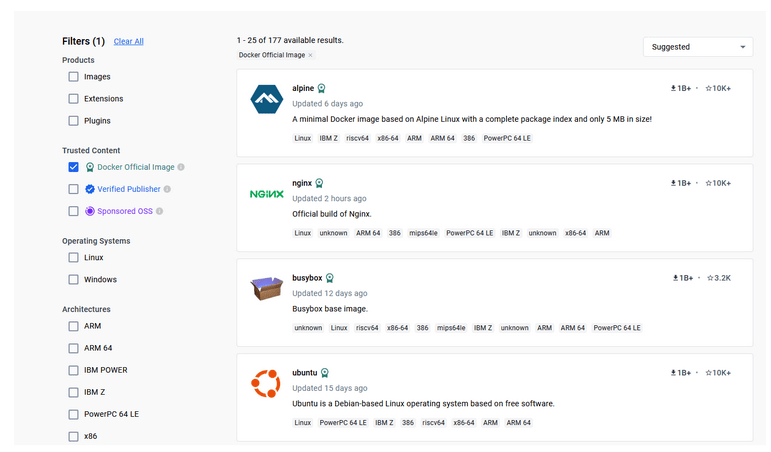
Rysunek 1 – Dockerhub, filtrowanie po oficjalnych obrazach
Używaj konkretnej wersji oprogramowania w obrazie i je aktualizuj – jeśli chcesz użyć do stworzenia swojego obrazu np. node, to pamiętaj, aby wyspecyfikować konkretną wersję, którą możesz znaleźć na Dockerhub. Jeśli nie wyspecyfikujesz tzw. tag’a zostanie pobrana najnowsza wersja – i to za każdym razem inna, jeśli będziesz w przyszłości przebudowywał swój obraz. Wybranie określonej wersji powoduje, że oprogramowanie jest kontrolowane i spójne tj. wiesz na jakim obrazie bazowym budujesz i masz pewność, że twoja aplikacja będzie działać. Powinno się jednak cyklicznie aktualizować i podnosić wersję na jakiej działa nasze oprogramowanie, należy to jednak robić w sposób kontrolowany przez dewelopera.

Rysunek 2 – node w serwisie Dockerhub, wspierane tagi, które możemy wybrać pisząc nasz plik Dockerfile
Używaj apt-get update i apt-get install -y w jednej linii – jeśli instalujemy wewnątrz naszego obrazu dodatkowe zewnętrzne paczki, z użyciem dowolnego menedżera pakietów (tutaj apt), to należy obie te komendy wpisać w tej samej linii i użyć linuksowego operatora &&. W przeciwnym wypadku mogą występować problemy ze zcache’owanymi warstwami.

Rysunek 3 – poprawne użycie apt-get update i install, źródło: dokumentacja Docker
Technika ta jest znana jako “cache busting”. Warto także specyfikować konkretne wersje oprogramowania, co jest znane jako “version pinning”. Zmusza to Docker’a do zwrócenia konkretnej wersji oprogramowania niezależnie od tego co występuje w cache.
Warto także wskazać, że to nie koniec problemów z wersją oprogramowania. Konkretne wersje powinniśmy też specyfikować w specjalnych plikach naszej aplikacji np. package.json czy requirements.txt. Generalna idea, jaka powinna nam przyświecać to “rób tak, aby mieć jak największą kontrolę nad wersjami oprogramowania, które instalujesz”.
Używaj jak najmniejszych obrazów oferujących minimum funkcjonalności do uruchomienia twojej aplikacji – wpłynie to pozytywnie na bezpieczeństwo oraz zmniejszy rozmiar budowanego obrazu. Unikaj obrazów mających niepotrzebnie dużo dodatkowych narzędzi/bibliotek, których twoja aplikacja nie używa. Zwiększa to powierzchnię ataku i wydłuża czas budowania, push’owania i pull’owania obrazów. Bardzo popularnym obrazem wykorzystywanym przy wielu innych obrazach, z których korzystają deweloperzy (np. autorzy node) jest alpine, którego podstawowa wersja waży jedyne 5MB. Jeśli więc twój obraz do node’a czy python’a ma w nazwie alpine, to dobry znak – znaczy, że jest prawdopodobnie zbudowany w optymalny sposób.
Używaj multi-stage build – jeśli język, którego używasz do programowania pozostawia pewne artefakty (produkty kompilacji), które następnie uruchamiasz, to warto zastanowić się nad podzieleniem pliku Dockerfile na dwie części – budowania oraz uruchamiania. Jeśli aplikacja napisana jest w języku Java, to możemy zainstalować zależności wyspecyfikowane w pliku pom.xml z użyciem maven’a. Komenda mvn package wyprodukuje nam działający plik .jar zawierający aplikację i wszystkie zależności, który w drugim kroku możemy uruchomić w zupełnie innym obrazie. Poniżej jest to jre, czyli java runtime environment w odpowiedniej wersji.
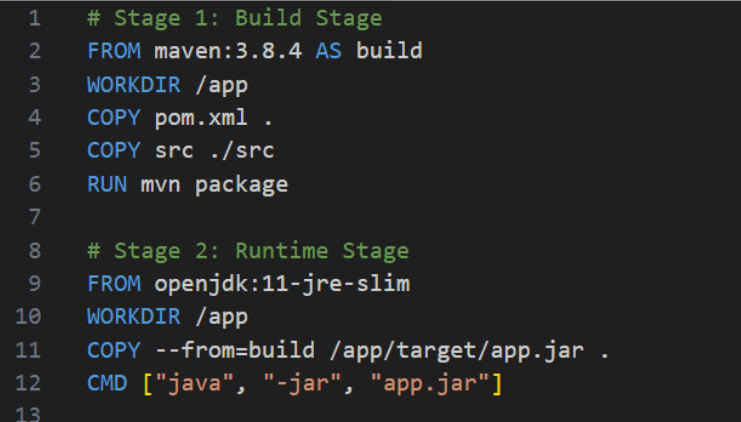
Rysunek 4 – plik Dockerfile z tzw. 2-stage-build
Zwróćmy także uwagę na komendę COPY w Stage 2 – ma ona flagę –from=build, gdzie build jest nazwą wyspecyfikowaną w drugiej linii pierwszego kroku. Oznacza to, że nie obciążamy wynikowego obrazu niepotrzebnymi zależnościami. Niektóre z obrazów działających w runtime reklamowane są w Internecie jako ‘distroless’, czyli mające bardzo odchudzone zależności bez menedżera pakietów czy shelli. W tym temacie polecamy artykuł Red Hat’a.
Podsumowanie
To już wszystko na dziś, ale na pewno nie jest to koniec wszystkich porad jakie mamy dla Was w kwestii Docker’a. Jeśli jesteście zainteresowani, to zachęcamy do lektury za tydzień, gdzie opracowujemy dla Was jeszcze więcej wartościowych treści, które wpłyną pozytywnie na jakość waszych projektów. Do usłyszenia za tydzień!
Źródła:



