Trenuj szybciej, mądrzej, lepiej – o technikach treningu modeli sieci neuronowych
Użycie sieci neuronowych w dzisiejszych czasach jest już tak powszechne, że ciężko znaleźć sektor gospodarki, w którym nie byłyby one wykorzystywane. Nadal jednak, mimo dostępu do niezliczonych badań, odpowiednie przygotowanie modelu (nawet do pozornie prostych zadań) jest bardzo często ogromnym wyzwaniem. Dzisiaj jako Innokrea chcielibyśmy zaprezentować Wam kilka stosunkowo prostych technik, które mogą znacząco poprawić jakość działania trenowanych sieci neuronowych. Zapraszamy do lektury!
Transfer Learning
Transfer Learning, które tłumaczyć możemy jako uczenie przechodnie, ma za zadanie skrócić czas konwergencji modelu. Podejście polega na tym, że zamiast uczenia sieci neuronowej “od zera”, to znaczy od losowo zainicjowanych wag, lepiej rozpocząć proces od wag modelu już kiedyś trenowanego na choć trochę podobnym typie danych – nawet, jeśli zadanie takiej sieci jest wyraźnie różniące się od obecnie obranego. Intuicję stojącą za tym pomysłem tłumaczyć można następującym przykładem z życia codziennego: studentowi medycyny, umiejącemu odczytać obraz USG, powinno być zdecydowanie łatwiej nauczyć się interpretacji obrazów rentgenowskich, niż osobie nie mającej pojęcia o obrazowaniu medycznym.
W praktyce transfer learning realizuje się poprzez pobranie z dostępnych repozytoriów (tzw. model zoo) wybranych wag pretrenowanych modeli i zainicjowanie na ich podstawie odpowiedniej architektury sieci neuronowej. Następnie, w zależności od tego, czy liczba klas w modelu wejściowym zgadza się z liczbą pożądaną w nowym zadaniu, może być konieczna modyfikacja (lub dodanie) warstwy wyjściowej tak, aby liczba neuronów odpowiadała wymaganej liczebności klas. Kolejnym – opcjonalnym – krokiem może być dalsza modyfikacja modelu oraz decyzja o zamrożeniu (ang. freezing) tych warstw architektury, których wag nie chcemy zmieniać (zazwyczaj będą to warstwy bliżej wejścia modelu). Od tego momentu trening jest wykonywany już w sposób standardowy.
Wiele współczesnych bibliotek (np. Pytorch) umożliwia bardzo proste inicjowanie modeli pretrenowanych, udostępniając własne model zoos. Zazwyczaj wystarczy wykorzystać jeden parametr inicjalizacji modelu i podać wybraną wersję wag (lub wybrać parametr domyślny) (np. ResNet50(weights=pretrained) pozwala wykorzystać pretrenowaną na zbiorze Imagenet [1] wersję architektury ResNet50 [2]).
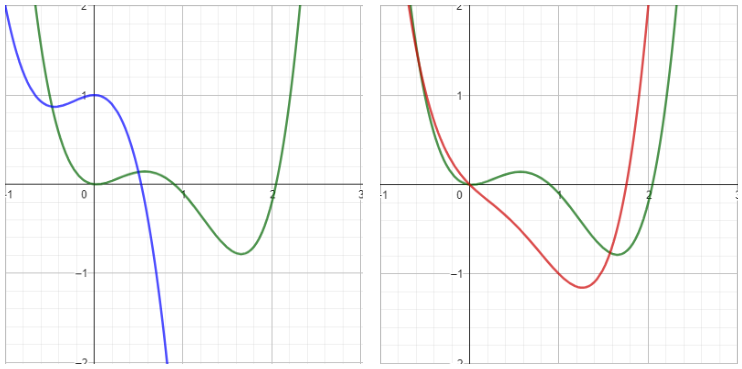
Rys. 1: Funkcja zielona jest docelową funkcją, do której model powinien się zbiegać podczas treningu. Po lewej: niebieska funkcja symbolizuje model z losowo zainicjowanymi wagami, po prawej: czerwona funkcja imituje użycie pretrenowanych wag modelu. Założyć można, że iteracyjna poprawa parametrów czerwonej funkcji tak, aby była ona podobna do funkcji docelowej wymaga mniej iteracji, niż odbyłoby się to w przypadku funkcji niebieskiej.
Domain Adaptation
Szczególną kategorią uczenia przechodniego jest tzw. domain adaptation. Polega ono na użyciu wytrenowanego już modelu, który jednak służył takiemu samemu (lub bardzo podobnemu) zadaniu. Przykładem może być użycie modelu określającego złośliwość zmian nowotworowych w płucach na zdjęciach z tomokomputera wykorzystywanego w szpitalu A i dostosowanie go do klasyfikacji zmian płucnych, ale na zdjęciach wykonywanych w innym szpitalu przy użyciu innego sprzętu. Innym przykładem domain adaptation jest dostosowanie tego modelu, aby rozpoznawać złośliwość zmian nowotworowych na zdjęciach tomograficznych, ale w obszarze głowy.
Trening to połowa sukcesu
Choć faza treningowa stawia przed deweloperami pewne wyzwania, to przy odrobinie pracy często można zaobserwować stopniową poprawę dokładności modelu na zbiorze treningowym w miarę upływu kolejnych epok treningowych. Niestety, to dopiero połowa sukcesu – aby symulować zachowanie modelu na nowych, “nieznanych” danych, należy zastosować walidację. Jeżeli nie wiesz, do czego służy walidacja w sieciach neuronowych, to zachęcamy do zapoznania się z naszym artykułem.
Częstym problemem obserwowanym przy próbach treningu modeli jest brak spadku (lub wzrost) wartości funkcji straty w fazie walidacji. Powodów takiego zjawiska może być wiele, ale wśród najpopularniejszych wymienić można m.in.: za mały zbiór treningowy czy za duży współczynnik uczenia (ang. learning rate). Podczas, gdy poprawa w przypadku ostatniego z wymienionych powodów jest trywialna, tak w przypadku pierwszego uzyskanie lepszych wyników może okazać się nieco bardziej pracochłonne. Znany jest jednak sprawdzony sposób na poprawę jakości modelu w takiej sytuacji: augmentacja danych.
Augmentacja danych
W momencie, w którym podejrzewamy, że mamy za mało danych, aby przeprowadzić skuteczny trening, zazwyczaj pierwsza myśl nie jest optymistyczna: muszę zdobyć więcej oznaczonych próbek! Podczas, gdy czasem zadanie to sprowadza się do pięciu minut przeszukania zasobów w internecie, to jednak zazwyczaj potrafi być znacznie bardziej skomplikowane. Na ratunek w takiej sytuacji przychodzą wszelkie techniki rozszerzania zbiorów, czyli wykorzystanie danych już posiadanych, z ich pewnymi modyfikacjami. W przypadku obrazów, wymienić możemy takie techniki jak: obracanie, przerzucanie w pionie lub poziomie, zmiana palety kolorów, przesunięcie… Oczywiście, w przypadku każdego zbioru należy zastanowić się, które z przekształceń nie wprowadzą dodatkowego szumu do danych (ang. noise) lub w ogóle nie zmienią klasy próbek – przykładowo, w problemie klasyfikacji koloru skóry osób na zdjęciach, za mocna manipulacja poziomem jasności obrazów mogłaby sprawić, że klasa, którą próbka reprezentowała przed augmentacją, teraz zupełnie nie pasuje już do wynikowego pliku i w konsekwencji konieczna jest dodatkowa ręczna korekta etykiet wszystkich “nowych” danych.

Rys. 2: Przykład augmentacji danych. Po lewej stronie obraz oryginalny, klasa “kwiat”. Po prawej 4 przykładowe sposoby przekształcenia go w taki sposób, aby zachować przynależność obrazu wyjściowego do początkowej klasy.
To wszystko na dziś, do zobaczenia!
Źródła:
[2] https://pytorch.org/vision/main/_modules/torchvision/models/resnet.html#resnet50