Sieci neuronowe: jak usprawnić, jak… hakować?

W ostatnim artykule udało nam się przeanalizować, jak wygląda dostrajanie parametrów sieci neuronowej w czasie fazy treningu. Dziś, jako Innokrea, opowiemy Wam parę słów o tym, jak ten proces treningu można przyspieszyć i poprawić, a także pokażemy, że choć (na dzień pisania artykułu) dokładność nowoczesnych architektur sztucznych sieci neuronowych bywa dziś nawet lepsza od dokładności człowieka, to jednak nie ma sieci nieomylnych – które nie poradzą sobie nawet z zadaniem, które dla człowieka byłoby absurdalnie proste. Zapraszamy do lektury!
Miliony OZNACZONYCH próbek?!
Zdecydowanie, jedną z największych blokad dla wielu małej i średniej wielkości korporacji przy próbach automatyzacji swoich procesów biznesowych jest brak dysponowania dużym zbiorem oznaczonych danych. Jeszcze większy problem pojawia się, jeżeli są to dane specjalistyczne, które oznaczać może jedynie wykwalifikowana osoba, np. lekarz, prawnik, czy rzeczoznawca – wówczas utworzenie takiego zbioru, który mógłby posłużyć jako dane treningowe do stworzenia modelu dla danej organizacji, wiąże się nie tylko z dużym nakładem czasowym, ale i finansowym. Często to już wystarczy, by skutecznie zniechęcić firmy do wdrożenia uczenia maszynowego w codzienne działania firmy.
Uczenie aktywne – jest ratunek
Dobra wiadomość dla wszystkich mierzących się z podobnym problemem: istnieją (i są coraz szerzej stosowane!) metody na to, by móc oznaczyć jedynie niewielką część danych z pewnego nieoznaczonego zbioru, a następnie na tym częściowo oznaczonym zbiorze wytrenować model, którego dokładność będzie bardzo zbliżona do działania modelu wytrenowanego na całym takim oznaczonym zbiorze! Jeżeli jest możliwe oznaczenie 30% danych zamiast 100% i uzyskanie bardzo podobnych rezultatów – to łatwo policzyć, jak wielka może to być dla firmy oszczędność czasu i zasobów materialnych!
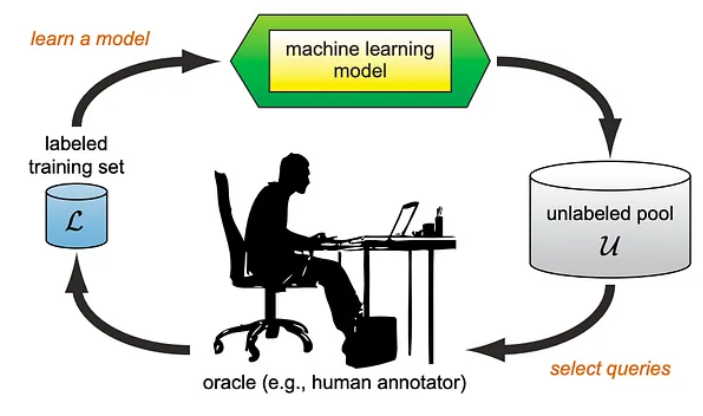
Rys. 1: Schemat uczenia aktywnego (źródło: Active Learning Literature Survey aut. Burr Settles et al) [1]
Jednym ze sposobów na osiągnięcie powyżej opisanego efektu jest zastosowanie tzw. uczenia aktywnego. Jest to, ogólnie rzecz ujmując, metoda polegająca na wybraniu do oznaczenia takich próbek danych ze zbioru, których oznaczenie będzie najbardziej informatywne dla modelu. Uczenie aktywne odbywa się zazwyczaj w rundach.
Przykładowo:
- Rozpoczynamy, podając do modelu małą część oznaczonych próbek ze zbioru (np. 5%).
- Trenujemy model przy użyciu tych danych.
- Następnie, model wykonuje próbę przypisania pozostałych 95% do klas.
- Na podstawie wyników tej próby, wybierane jest kolejne 5% danych, które należy oznaczyć. Kryterium wyboru może być np. to, jak niepewny był model w najpewniejszej z klas lub to, jak niewielka była różnica między dwoma najbardziej prawdopodobnymi klasami.
Aby to zobrazować, rozważmy wyniki klasyfikacji trójklasowej dla dwóch próbek:
Próbka A: [0.4, 0.55, 0.05]
Próbka B: [0.25, 0.25, 0.5].
Jeżeli zastosowalibyśmy pierwszą z opisanych metod wyboru, to do ręcznego oznaczenia wybrana zostałaby próbka B – prawdopodobieństwo najbardziej prawdopodobnej klasy tutaj jest niższe, niż w przypadku próbki A (0.5 < 0.55).
W drugim przypadku natomiast, ręcznie oznaczona miałaby zostać próbka A – jako, że różnica między prawdopodobieństwami dwóch najbardziej prawdopodobnych klas jest mniejsza, niż w przypadku próbki B (0.55-0.4 < 0.5-0.25).
- Procedurę tę opisaną w trzech poprzednich krokach powtarzamy aż do momentu oznaczenia ustalonej części zbioru (np. 30%) lub do momentu, w którym model będzie “wystarczająco pewny” klas pozostałych próbek (ustala się to zazwyczaj za pomocą jakiegoś parametru lub stosuje bardziej złożone metody, w które nie będziemy się tu zagłębiać).
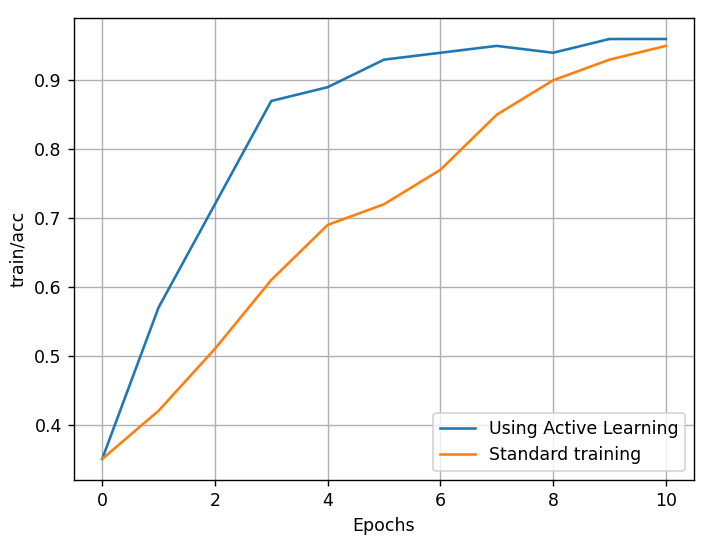
Rys. 2: Porównanie tempa uczenia modelu z uczeniem aktywnym i bez
Oczywiście, to nie jedyna metoda umożliwiająca znaczną redukcję liczby próbek koniecznych do oznaczenia w danym zbiorze. Innym ciekawym podejściem jest np. metoda polegająca na przetransformowaniu próbek w wektory ich cech (ang. feature extraction), pogrupowanie względem podobieństw w określoną liczbę grup (ang. clustering), a następnie wybranie reprezentantów tych grup do oznaczenia ręcznego. Po takim oznaczeniu, etykiety są propagowane na resztę próbek konkretnej grupy.
Tego typu metody często określa się w literaturze jako human-in-the-loop machine learning.
Czy sieć da się… Zhakować?
Aby odpowiedzieć na to pytanie, zadamy jedno pytanie: co widzisz na prawym i lewym obrazku?

Rys. 3: Dwa obrazki
Tak, dla człowieka odpowiedź jest prosta – to ten sam obraz.
W przypadku sieci neuronowej, możemy jednak zostać mocno zaskoczeni!

Rys. 4: Błąd sieci neuronowej po zamianie koloru jednego piksela obrazu
Zaskakujące? Jak najbardziej! Okazuje się, że praktycznie dowolną sieć neuronową można w taki sposób oszukać – ludzkie oko nie zauważy żadnej różnicy, natomiast przy odpowiednio opracowanej zamianie koloru piksela czy nałożeniu bardzo nieznacznej maski na obraz, dane w sieci neuronowej mogą zostać rozpoznane w sposób zupełnie nieprzewidywalny. Ciekawym tematu polecamy artykuły:
- One pixel attack for fooling deep neural networks [2]
- Explaining and Harnessing Adversarial Examples [3]
I tym akcentem kończymy naszą serię artykułów o sieciach neuronowych – do usłyszenia za tydzień!
Źródła:
[1] Burr Settles. Active Learning Literature Survey. Computer Sciences Technical Report 1648, University of Wisconsin–Madison. 2009
[2] https://arxiv.org/abs/1710.08864
[3] https://arxiv.org/abs/1412.6572



